Livello 7: applicazione (Application Layer)
Il livello 7 prende il nome di “applicazione” poichè fornisce alle applicazioni i protocolli necessari alla comunicazione con applicazioni che sono eseguite su altri host. Non bisogna quindi confondere applicazioni e protocolli utilizzati.
Indice
Obiettivo: permettere alle applicazioni di comunicare con applicazioni in esecuzione su un altro host.
Protocolli
Esistono moltissimi protocolli utilizzati dalle applicazioni per svolgere svariati compiti come: trasferimento file, terminale virtuale, posta elettronica, risoluzione di nomi di dominio… Di seguito è riportato un elenco di protocolli.
- DHCP
- DNS
- HTTP
- HTTPS
- SMTP
- SNMP
- POP3
- FTP
- Network Time Protocol (NTP)
- Telnet
- Secure shell (SSH)
- IRC
- Lightweight Directory Access Protocol (LDAP)
- XMPP
- FTAM
- Advanced Program to Program Communications (APPC)
- X.400
- X.500
- AFP
- SIP
- ITMS
- AIM
- TFTP
- NNTP
- Modbus TCP
Prima di trattare nello specifico le funzionalità offerte dai vari protocolli è necessario conoscere alcuni aspetti generali della comunicazione a livello applicazione.
URI e URL
lo Uniform Resource Identifier (in acronimo URI) è una sequenza di caratteri che identifica universalmente ed univocamente una risorsa. Un URI può essere classificato come qualcosa che definisce posizioni (URL) o nomi (URN) o entrambi.
Un URN (Uniform Resource Name) è un URI che identifica una risorsa mediante un “nome” in un particolare dominio di nomi (“namespace”). Un URN può quindi essere usato per identificare una risorsa, senza lasciarne intendere l’ubicazione o come ottenerne una rappresentazione. Per esempio l’URN urn:isbn:0-395-36341-1 è un URI che mappa universalmente e univocamente un libro mediante il suo identificativo, o nome, (0-395-36341-1) nel namespace dei codici ISBN, ma non suggerisce dove e come possiamo ottenere una copia di tale libro. Si noti che, da RFC8141, un URN è un URI assegnata sotto lo schema URI “urn”.
Un URL (Uniform Resource Locator) è un URI che identifica una risorsa tramite la sua “collocazione” (“location”). Di fatto, non identifica la risorsa per nome, ma con il modo con cui la si può reperire. Per esempio, l’URL http://www.example.com/ è un URI che identifica una risorsa (l’home page di un sito web) e lascia intendere che una rappresentazione di tale risorsa (il codice HTML della versione corrente di tale home page) è ottenibile via HTTP da un host di rete chiamato www.example.com.
Lo schema completo di una URL è del tipo (non tutte le componenti sono obbligatorie):
<scheme>://<domain>:<port>/<path>?<querystring>#<fragmentid>
esempi di url sono:
- ftp://ftp.is.co.za/rfc/rfc1808.txt - schema per servizi FTP
- http://www.math.uio.no/faq/compression-faq/part1.html - schema per servizi HTTP
- file://C:/Folder1/SubFolder2/file%20text.txt - schema per un file nel file system locale
- mailto:mduerst@ifi.unizh.ch - schema per indirizzi di posta elettronica
- news:comp.infosystems.www.servers.unix - schema per newsgroup e articoli Usenet
- telnet://melvyl.ucop.edu/ - schema per servizi interattivi telnet
- irc://irc.freenode.net/wikipedia-it - schema per IRC
- spotify:artist:6wWVKhxIU2cEi0K81v7HvP - schema per brani su Spotify
- usb://Samsung/SCX-4x21%20Series?serial=8P36BADL316673B.&interface=1 - Esempio di stampante in ambiente Linux
I protocolli di livello applicazione usano normalmente gli URL, ma è stato detto in precedenza che per creare un canale di comunicazione tra due host si crea una socket che è formata da indirizzo IP e porta. In questo caso l’indirizzo IP non è indicato, si identifica invece l’host contenente la risorsa per mezzo di un nome di dominio, indicato nella struttura dell’url come domain. Per instaurare una comunicazione è necessario quindi l’utilizzo di un servizio che converta i nomi di dominio in indirizzi IP, questo servizio è il Domain Name System (DNS).
DNS
il sistema dei nomi di dominio (in inglese: Domain Name System, DNS), è un sistema utilizzato per assegnare nomi ai nodi della rete (host). Questi nomi sono utilizzabili, mediante una traduzione, di solito chiamata “risoluzione”, al posto degli indirizzi IP originali. Il servizio è realizzato tramite un database distribuito, costituito dai server DNS. Il DNS ha una struttura gerarchica ad albero rovesciato ed è diviso in domini (com, org, it, ecc.). Ad ogni dominio o nodo corrisponde un nameserver, che conserva un database con le informazioni di alcuni domini di cui è responsabile e si rivolge ai nodi successivi quando deve trovare informazioni che appartengono ad altri domini.
Ogni nome di dominio termina con un “.” (punto). Ad esempio l’indirizzo wikipedia.org termina con il punto. La stringa che segue il punto finale è chiamata “dominio radice” (DNS root zone). I server responsabili del dominio radice sono i cosiddetti root nameservers. Essi possiedono l’elenco dei server autoritativi di tutti i domini di primo livello (TLD) riconosciuti e lo forniscono in risposta a ciascuna richiesta. I root nameserver sono 13 in tutto il mondo, di cui 10 negli Stati Uniti, due in Europa (Inghilterra e Svezia) e uno in Giappone.
Storia
Il DNS fu ideato il 23 giugno 1983 da Paul Mockapetris, Jon Postel e Craig Partridge; le specifiche originali sono descritte nello standard RFC 882. Nel 1987 vennero pubblicati commenti allo standard RFC del DNS, con i nomi RFC 1034 e RFC 1035 rendendo obsolete le specifiche precedenti.
Descrizione
Il nome DNS denota anche il protocollo di livello 7 che regola il funzionamento del servizio, i programmi che lo implementano, i server su cui questi vengono elaborati, l’insieme di questi server che cooperano per fornire il servizio più intelligente.
I nomi DNS, o “nomi di dominio” o “indirizzi mnemonici”, sono una delle caratteristiche più visibili di Internet. L’operazione di conversione da nome a indirizzo IP è detta “risoluzione DNS”; la conversione da indirizzo IP a nome è detta “risoluzione inversa”.
In pratica, il DNS è un registro universale cioè un database distribuito, con una struttura gerarchica, che archivia i nomi mnemonici di dominio e la loro associazione ai relativi indirizzi IP specifici.
Motivazioni ed utilizzi
- La possibilità di attribuire un nome testuale facile da memorizzare a un server (ad esempio un sito world wide web) migliora di molto l’uso del servizio, in quanto gli esseri umani trovano più facile ricordare nomi testuali (mentre gli host e i router sono raggiungibili utilizzando gli indirizzi IP numerici). Per questo, il DNS è fondamentale per l’ampia diffusione di internet anche tra utenti non tecnici, ed è una delle sue caratteristiche più visibili.
- È possibile attribuire più nomi allo stesso indirizzo IP (o viceversa) per rappresentare diversi servizi o funzioni forniti da uno stesso host (o più host che erogano lo stesso servizio). Questa “flessibilità” risulta utile in molti casi:
- Nel caso in cui si debba sostituire il server che ospita un servizio, o si debba modificare il suo indirizzo IP, è sufficiente modificare il record DNS, senza dover intervenire sui client.
- Utilizzando nomi diversi per riferirsi ai diversi servizi erogati da uno stesso host (registrati quindi con lo stesso indirizzo IP), è possibile spostare una parte dei servizi su un altro host (con diverso indirizzo IP, già predisposto a fornire i servizi in oggetto). Modificando quindi sul server DNS i record dei nomi associati ai servizi da spostare e registrando il nuovo IP al posto di quello vecchio, si otterrà lo spostamento automatico delle nuove richieste di tutti i client su questo nuovo host, senza interruzione dei servizi.
- Un utilizzo molto popolare di questa possibilità è il cosiddetto virtual hosting, basato sui nomi, una tecnica per cui un web server dotato di una singola interfaccia di rete e di singolo indirizzo IP può ospitare più siti web, usando l’indirizzo alfanumerico trasmesso nell’header HTTP per identificare il sito per cui viene fatta la richiesta.
- Facendo corrispondere a un nome più indirizzi IP, il carico dei client che richiedono quel nome viene distribuito sui diversi server associati agli IP registrati, ottenendo un aumento delle prestazioni complessive del servizio e una tolleranza ai guasti (ma è necessario assicurarsi che i diversi server siano sempre allineati, ovvero offrano esattamente lo stesso servizio ai client).
- La risoluzione inversa è utile per identificare l’identità di un host, o per leggere il risultato di un traceroute.
- Il DNS viene usato da numerose tecnologie in modo poco visibile agli utenti, per organizzare le informazioni necessarie al funzionamento del servizio.
Nomi di dominio
Un nome di dominio è costituito da una serie di stringhe separate da punti, ad esempio it.wikipedia.org. e sono organizzati a livelli. A differenza degli indirizzi IP, dove la parte più importante del numero è la prima cifra partendo da sinistra, in un nome DNS la parte più importante è la prima partendo da destra.
La parte più a destra è detta dominio di primo livello (o TLD, Top Level Domain), e ce ne sono centinaia che possono essere scelti, per esempio .org o .it.
Un dominio di secondo livello, a differenza del dominio di primo livello che è formato da parole “fisse” e limitate, è formato da una parola scelta a piacimento. Questa parola deve il più possibile essere legata a quello che ci identifica e a quello che vogliamo comunicare. Il dominio di secondo livello è quindi formato da due parti, per esempio wikipedia.org, e così via.
Il dominio di terzo livello è il figlio del dominio di secondo livello, infatti, prendendo come esempio wikipedia.org, un dominio di terzo livello sarà: stuff.wikipedia.org. Ogni ulteriore elemento specifica quindi un’ulteriore suddivisione. Quando un dominio di secondo livello viene registrato all’assegnatario, questo è autorizzato a usare i nomi di dominio relativi ai successivi livelli, come some.other.stuff.wikipedia.org (dominio di quinto livello) e così via.
Un nome di dominio, come per esempio it.wikipedia.org, può essere parte di un URL, come http://it.wikipedia.org/wiki/Treno, o di un indirizzo e-mail, come per esempio apache@it.wikipedia.org. È anche possibile connettersi a un sito con il protocollo telnet oppure usare una connessione FTP usando il suo nome a dominio.
Sistema DNS in Internet
Qualsiasi rete IP può usare il DNS per implementare un suo sistema di nomi privato. Tuttavia, il termine “nome di dominio” è più comunemente utilizzato quando esso si riferisce al sistema pubblico dei DNS su Internet. Il sistema del DNS è organizzato in modo gerarchico secondo quello che viene chiamato un albero rovesciato.
In cima alla gerarchia si trovano 13 server universali detti root server i quali devono conoscere almeno le collocazioni di tutti nameserver di primo livello. I root server hanno nomi di dominio che vanno da a.root-servers.net a m.rootservers.net e i loro IP sono noti (qui puoi trovare la lista oltre ad altri approfondimenti).
I server di primo livello si occupano di gestire i nomi di dominio che competono loro, esisteranno quindi uno o più server di primo livello che gestiscono il dominio .com altri che gestiscono il dominio .it…
Esistono poi altri server ad un livello inferiore che gestiscono i vari domini registrati. In alcuni casi ad un dominio di secondo livello corrisponde un server DNS che gestisce quel dominio compreso tutti i nomi di livello successivo ad esso associati. In molti casi invece i nomi di dominio sono registrati presso server che gestiscono un gran numero di nomi di dominio come ad esempio Aruba, AWS…
Ogni volta che un host vuole risolvere un nome di dominio di cui non conosca già l’IP corrispondente, interroga un server DNS o nameserver a sua scelta, il quale, se conosce la risposta, la manda all’host. Quando un nameserver riceve una interrogazione a cui non sa dare risposta, ha due possibilità, se la domanda riguarda un sottodominio del dominio da lui gestito, passa la domanda al nameserver di competenza (ad es. se viene chiesto al nameserver responsabile del dominio .org di risolvere it.wikipedia.org, la domanda viene passata al nameserver di livello inferiore che gestisce il dominio wikipedia), se invece l’interrogazione riguarda un altro dominio, il nameserver passa la domanda ad un superiore (ad es. se viene chiesto al nameserver responsabile del dominio .it di risolvere wikipedia.org la domanda dovrebbe essere passata al rootserver).
La struttura gerarchica ad albero del sistema DNS permette in un numero limitato di passaggi di raggiungere il server competente per lo specifico nome richiesto.
Teoricamente per arrivare ad ogni spazio di dominio si dovrebbe passare spesso dai rootserver che però sono pochi per riuscire a servire continuamente tutti gli host del mondo. Nella pratica però la maggior parte delle informazioni fornite dai root nameserver non cambia molto spesso e viene memorizzata in varie cache (memoria temporanea) da una gerarchia di server DNS cui si rivolgono i singoli computer prima di interrogare i nameserver principali; anzi, quando viene fatta una richiesta di informazioni la risposta contiene anche l’informazione su per quanto tempo essa può essere ritenuta valida, proprio per rendere le richieste di risoluzione DNS ai root nameserver relativamente rare.
Esistono alcuni nameserver che non gestiscono uno spazio di dominio particolare ma per motivi vari (analisi del traffico dati per scopi privati?) offrono gratuitamente il servizio DNS aggiungendo in alcuni casi anche altri servizi come ad esempio il blocco di siti pericolosi. Qui puoi trovare un articolo che descrive 12 diversi DNS pubblici.
HTTP
HTTP (HyperText Transfer Protocol - protocollo di trasferimento di un ipertesto) è un protocollo a livello applicativo usato come principale sistema per la trasmissione d’informazioni sul web in una architettura client-server. Le specifiche del protocollo sono gestite dal World Wide Web Consortium (W3C). Un server HTTP generalmente resta in ascolto delle richieste dei client sulla porta 80 usando il protocollo TCP a livello di trasporto.
Storia
La prima versione dell’HTTP, la 0.9, risale alla fine degli anni 1980 e costituiva, insieme con il linguaggio HTML e gli URL, il nucleo base del World Wide Web (WWW) sviluppata da Tim Berners-Lee al CERN di Ginevra per la condivisione delle informazioni tra la comunità dei fisici delle alte energie. Prima di HTTP il protocollo di riferimento per tali scopi era il più semplice e leggero FTP. La prima versione effettivamente disponibile del protocollo, la HTTP/1.0, venne implementata dallo stesso Berners-Lee nel 1991 e riconosciuta come standard nel 1996.
Negli anni il WWW conobbe un successo crescente e divennero evidenti alcuni limiti della versione 1.0 del protocollo, in particolare:
- l’impossibilità di ospitare più siti web sullo stesso server (virtual hosting, argomento interessante ma complesso, non lo tratteremo);
- il mancato riuso delle connessioni disponibili;
- l’insufficienza dei meccanismi di sicurezza.
Per far fronte ai primi due problemi il protocollo venne aggiornato alla versione 1.1 nel 1999 (e poi alla 2.0 nel 2014). Per risolvere i problemi di sicurezza è stato sviluppato invece HTTPS che sfrutta protocolli crittografici a livello di presentazione.
Funzionamento
L’HTTP è un protocollo che lavora con un’architettura di tipo client/server: il client esegue una richiesta e il server restituisce la risposta mandata da un altro host. Nell’uso comune il client corrisponde al browser ed il server la macchina su cui risiede il sito web. Vi sono quindi due tipi di messaggi HTTP: messaggi richiesta e messaggi risposta.
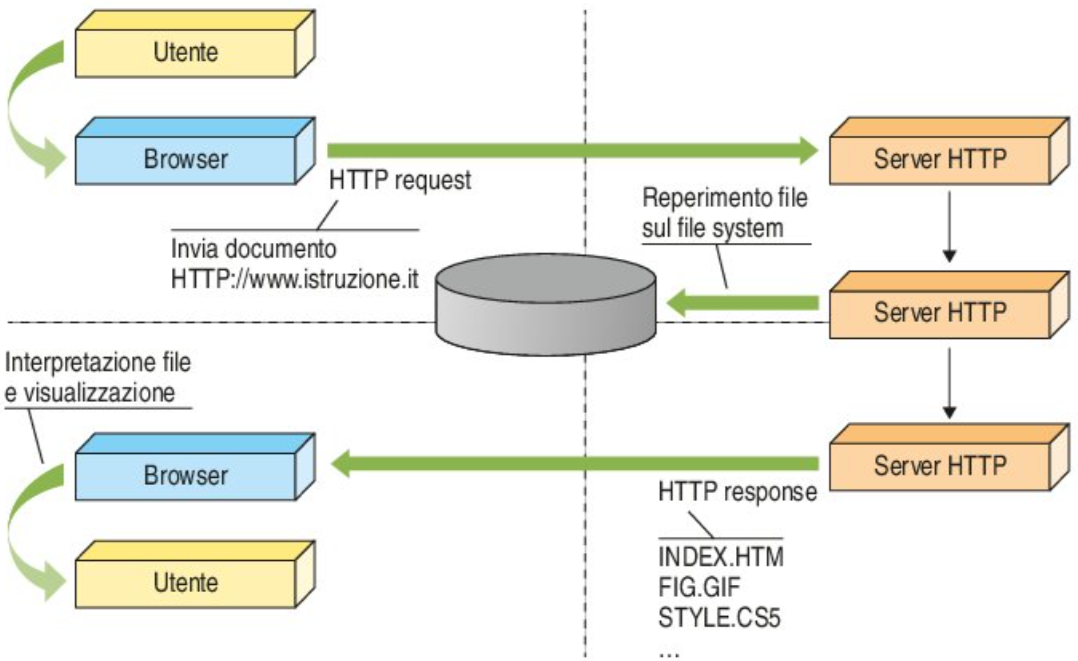
Schema di funzionamento di una richiesta di risorsa (una pagina web) da parte di un browser (client) e conseguente risposta di un server HTTP
Schema di funzionamento di una richiesta di risorsa (una pagina web) da parte di un browser (client) e conseguente risposta di un server HTTP
HTTP differisce da altri protocolli di livello 7 come FTP, per il fatto che le connessioni vengono generalmente chiuse una volta che una particolare richiesta (o una serie di richieste correlate) è stata soddisfatta. Questo comportamento rende il protocollo HTTP ideale per il World Wide Web, in cui le pagine molto spesso contengono dei collegamenti (link) a pagine ospitate da altri server diminuendo così il numero di connessioni attive limitandole a quelle effettivamente necessarie con aumento quindi di efficienza (minor carico e occupazione) sia sul client che sul server. Talvolta però pone problemi agli sviluppatori di contenuti web, perché la natura senza stato (stateless) della sessione di navigazione costringe ad utilizzare dei metodi alternativi - tipicamente basati sui cookie - per conservare lo stato dell’utente.
Messaggio di richiesta
Il messaggio di richiesta è composto di quattro parti:
GET /wiki/Pagina_principale HTTP/1.1
Host: it.wikipedia.org
User-Agent: Mozilla/5.0 (compatible; Konqueror/3.2; Linux) (KHTML, like Gecko)
Accept: text/html, image/jpeg, image/png, text/*, image/*, */*
Accept-Charset: iso-8859-1, utf-8;q=0.5, *;q=0.5
Accept-Language: it
Connection: Keep-Alive
- riga di richiesta (request line): che a sua volta è composta da:
- metodo (i primi tre dei seguenti metodi sono i più importanti e usati)
- GET: usato per richiedere una risorsa, è possibile aggiungere parametri all’url
- POST: usato per inviare al server una serie di coppie di valori name=value usate come input per la risorsa richiesta indicata dall’URL
- HEAD: simile a get ma richiede come risposta solo l’header e non il body, allo scopo di avere solo informazioni sulla risorsa, di solito per testare accessibilità alla risorsa o scoprire se sono disponibili modifiche dall’ultima richiesta
- PUT:
- DELETE:
- PATCH
- TRACE
- OPTIONS
- CONNECT
- URL
- Versione del protocollo
- metodo (i primi tre dei seguenti metodi sono i più importanti e usati)
- sezione header (informazioni aggiuntive), i più comuni sono:
- Host: nome del server a cui si riferisce l’URL; è obbligatorio nelle richieste conformi HTTP/1.1 perché permette l’uso dei virtual host basati sui nomi.
- User-Agent: identificazione del tipo di client: tipo browser, produttore, versione…
- Cookie: utilizzati dalle applicazioni web per archiviare e recuperare informazioni a lungo termine sul lato client; spesso usati per memorizzare un token di autenticazione o per tracciare le attività dell’utente.
- riga vuota (CRLF: i 2 caratteri carriage return e line feed), essenzialmente un separatore tra intestazione e body;
- body (corpo del messaggio), usato quando ci sono effettivamente dati da trasferire (non è il caso del GET, lo è invece del POST).
Messaggio di risposta
HTTP/1.1 200 OK
Date: Fri, 22 Feb 2019 10:50:37 GMT
Content-Type: text/html; charset=UTF-8
Content-Length: 22208
Connection: keep-alive
Server: mw1215.eqiad.wmnet
Content-language: it
Content-Encoding: gzip
Last-Modified: Fri, 22 Feb 2019 08:46:20 GMT
Age: 20548
Cache-Control: private, s-maxage=0, max-age=0, must-revalidate
Vary: Accept-Encoding,Cookie,Authorization
[...]
<!DOCTYPE html>
<html class="client-nojs" lang="it" dir="ltr">
<head>
<meta charset="UTF-8"/>
<title>Wikipedia, l'enciclopedia libera</title>
[...]
</body>
</html>
Il messaggio di risposta è di tipo testuale ed è composto da quattro parti:
- riga di stato (status-line):
ha una grande importanza soprattutto per gli sviluppatori poichè qui è indicato un codice a tre cifre che indica il tipo di risposta che può appartenere alle seguenti categorie:- 1xx: Informational (messaggi informativi)
- 2xx: Successful (la richiesta è stata soddisfatta), ad es.:
- 200 OK. Il server ha fornito correttamente il contenuto nella sezione body.
- 3xx: Redirection (non c’è risposta immediata, ma la richiesta è sensata e viene detto come ottenere la risposta) ad es.:
- 301 Moved Permanently. La risorsa che abbiamo richiesto non è raggiungibile perché è stata spostata in modo permanente.
- 302 Found. La risorsa è raggiungibile con un altro URI indicato nel header Location. Di norma i browser eseguono la richiesta all’URI indicato in modo automatico senza interazione dell’utente.
- 4xx: Client error (la richiesta non può essere soddisfatta perché sbagliata)
- 400 Bad Request. La risorsa richiesta non è comprensibile al server.
- 404 Not Found. La risorsa richiesta non è stata trovata e non se ne conosce l’ubicazione. Di solito avviene quando l’URI è stato indicato in modo incorretto, oppure è stato rimosso il contenuto dal server.
- 5xx: Server error (la richiesta non può essere soddisfatta per un problema interno del server)
- 500 Internal Server Error. Il server non è in grado di rispondere alla richiesta per un suo problema interno.
- 502 Bad Gateway. Il server web che agisce come reverse proxy non ha ottenuto una risposta valida dal server di upstream.
- 505 HTTP Version Not Supported. La versione di http non è supportata.
- sezione header, i più comuni sono:
- Server. Indica il tipo e la versione del server. Può essere visto come l’equivalente dell’header di richiesta User-Agent
- Content-Type. Indica il tipo di contenuto restituito come:
- text/html Documento HTML
- text/plain Documento di testo non formattato
- text/xml Documento XML
- image/jpeg Immagine di formato JPEG
- riga vuota (CRLF: i 2 caratteri carriage return e line feed);
- body (contenuto della risposta).
In questa sezione sono stati riportati solo due esempi di messaggi HTTP, una richiesta di tipo GET e una risposta possibile a tale domanda. Sulla pagina di Wikipedia da cui sono state tratte queste informazioni è possibile trovare molti altri esempi ed approfondimenti.
Tipo di connessione
Il client può chiedere al server, nel messaggio di richiesta, di utilizzare due tipi di comunicazione:
- non persistente: per ogni richiesta e relativa risposta, viene stabilita una connessione TCP dedicata;
- persistente: ogni richiesta e relativa risposta è trasferita utilizzando la stessa connessione TCP; è il comportamento predefinito di HTTP 1.1.
Da un lato, le connessioni non persistenti introducono una latenza aggiuntiva rispetto a quelle persistenti perchè aprire e chiudere una connessione TCP introduce dell’overhead. D’altro canto, le connessioni persistenti precludono il parallelismo nelle comunicazioni, giacché il client che abbia diverse richieste da inviare allo stesso server è costretto ad evaderle sequenzialmente, una dopo l’altra. Per queste ragioni, i browser solitamente sfruttano le complementarità prestazionali delle due politiche di comunicazione per massimizzare la loro efficienza: solitamente aprono con ogni server diverse connessioni TCP in parallelo, su cui comunicano con strategia persistente.
Streaming HTTP
La fruizione nelle pagine WEB di materiale multimediale, quale audio o video viene gestito in modo del tutto analogo al download dei file, tramite un caricamento progressivo o distribuzione progressiva, in cui il file viene scaricato in modo progressivo dall’inizio alla fine (tramite i protocolli Real Time Streaming Protocol e Real-time Transport Protocol) e nel caso il bit-rate sia eccessivo per la rete che lo trasporta può verificarsi un continuo ricaricamento del buffer
Cookies
Il protocollo HTTP è un protocollo stateless cioè non tiene traccia dello stato della connessione. Se la comunicazione si limitasse all’uso delle funzionalità offerte da HTTP quindi ad ogni richiesta di un client il server risponderebbe come se fosse la prima volta che il client comunica con lui. Per tenere traccia dello stato della comunicazione sono quindi stati introdotti i cookies che funzionano come dei gettoni identificativi che i server rilasciano ai client e in cui memorizzano informazioni a lungo termine.
I server inviano i cookie nella risposta HTTP al client e ci si aspetta che i web browser salvino e inviino i cookie al server, ogni qual volta si facciano richieste aggiuntive al web server. Tale riconoscimento permette di realizzare meccanismi di autenticazione usati ad esempio per i login; di memorizzare dati utili alla sessione di navigazione, come le preferenze sull’aspetto grafico o linguistico del sito; di tracciare la navigazione dell’utente, ad esempio per fini statistici o pubblicitari; di associare dati memorizzati dal server, ad esempio il contenuto del carrello di un negozio elettronico.
Date le implicazioni per la riservatezza dei naviganti del web, l’uso dei cookie è categorizzato e disciplinato negli ordinamenti giuridici di numerosi paesi, tra cui quelli europei, inclusa l’Italia. Tra le varie regole dettate dalla legge, quella più evidente per l’utente è che i server devono ricevere un esplicito permesso da parte dell’utente per poter utilizzare i cookies.
In termini pratici e non specialistici, un cookie è simile ad un piccolo file, memorizzato nel computer da siti web durante la navigazione, utile a salvare le preferenze e a migliorare le prestazioni dei siti web. In questo modo si ottimizza l’esperienza di navigazione da parte dell’utente.
Nel dettaglio, un cookie è una stringa di testo di piccole dimensioni inviata da un web server ad un web client (di solito un browser) e poi rimandata indietro dal client al server (senza subire modifiche) ogni volta che il client accede alla stessa porzione dello stesso dominio web. I cookie sono stati originariamente introdotti per fornire un modo agli utenti di memorizzare gli oggetti che volevano acquistare, mentre navigavano nel sito web (il cosiddetto “carrello della spesa”).
Oggi, tuttavia, il contenuto del carrello di un utente viene immagazzinato in un database sul server, piuttosto che in un cookie sul client. Per tenere traccia a quale utente è assegnato il carrello della spesa, il server Web invia un cookie al client che contiene un identificatore di sessione univoco (tipicamente, una lunga serie di lettere e numeri). Poiché i cookie vengono inviati al server ad ogni richiesta del client, l’identificatore di sessione sarà inviato al server ogni volta che l’utente visita una pagina sul sito web, ciò permette al server di sapere quale carrello deve fornire all’utente.
Poiché i cookie di sessione contengono solo un identificatore di sessione univoco, questo rende la quantità di informazioni personali che un sito web può memorizzare virtualmente illimitata. Il sito non si limita alle restrizioni in materia di quanto possa essere lunga la stringa di testo che compone un cookie. I cookie di sessione possono anche contribuire a migliorare i tempi di caricamento delle pagine, dal momento che la quantità di informazioni in un cookie di sessione è piccolo e richiede poca banda.
I cookie vengono spesso erroneamente ritenuti veri e propri programmi e ciò genera errate convinzioni. In realtà essi sono semplici blocchi di dati, incapaci, da soli, di compiere qualsiasi azione sul computer. In particolare non possono essere né spyware, né virus. Ciononostante i cookie provenienti da alcuni siti sono catalogati come spyware da molti prodotti anti-spyware perché rendono possibile l’individuazione dell’utente. I moderni browser permettono agli utenti di decidere se accettare o no i cookie, ma l’eventuale rifiuto rende alcuni oggetti inutilizzabili. Ad esempio, gli shopping cart implementati con i cookie non funzionano in caso di rifiuto.
La grande varietà esistente di cookie nel mondo del web rende difficile una loro classificazione. È possibile comunque stilarne una tassonomia generale separandoli in diverse categorie.
L’attributo principale tramite cui possiamo dividere i cookie è il loro ciclo di vita, il quale ci permette di distinguerli in:
- Cookie di sessione: questi cookie non vengono memorizzati in modo persistente sul dispositivo dell’utente e vengono cancellati alla chiusura del browser. A differenza di altri cookie, i cookie di sessione non hanno una data di scadenza, ed in base a questo il browser riesce ad identificarli come tali.
- Cookie persistenti: invece di svanire alla chiusura del browser, come vale per i cookie di sessione, i cookie persistenti scadono ad una data specifica o dopo un determinato periodo di tempo. Ciò significa che, per l’intera durata di vita del cookie (che può essere lunga o breve a seconda della data di scadenza decisa dai suoi creatori), le sue informazioni verranno trasmesse al server ogni volta che l’utente visita il sito web, o ogni volta che l’utente visualizza una risorsa appartenente a tale sito da un altro sito (ad esempio un annuncio pubblicitario). Per questo motivo, i cookie persistenti possono essere utilizzati dagli inserzionisti per registrare le informazioni sulle abitudini di navigazione web di un utente per un periodo prolungato di tempo. Tuttavia, essi sono utilizzati anche per motivi “legittimi “ (come ad esempio mantenere gli utenti registrati nel loro account sui siti web, al fine di evitare, ad ogni visita, l’inserimento delle credenziali per l’accesso ai siti web).
È possibile poi classificare i cookie in base alla provenienza in:
- Cookie di prima parte: normalmente, l’attributo di dominio di un cookie corrisponderà al dominio che viene visualizzato nella barra degli indirizzi del browser web; sono i cookie inviati al browser direttamente dal sito che si sta visitando. Questo è chiamato un cookie di prima parte. Possono essere sia persistenti sia di sessione; sono gestiti direttamente dal proprietario e/o responsabile del sito e vengono utilizzati, ad esempio, per garantirne il funzionamento tecnico o tenere traccia di preferenze espresse in merito all’uso del sito stesso.
- Cookie di terza parte: i cookie di terze parti, appartengono a domini diversi da quello mostrato nella barra degli indirizzi. Questi tipi di cookie appaiono in genere quando le pagine web sono dotate di contenuti, come ad esempio banner pubblicitari, da siti web esterni. Questo implica la possibilità di monitoraggio della cronologia di navigazione dell’utente, ed è spesso usato dagli inserzionisti, nel tentativo di servire annunci rilevanti e personalizzati per ciascun utente. Per esempio, supponiamo che un utente visiti www.example.org. Questo sito web contiene un annuncio da ad.foxytracking.com, che, una volta scaricato, imposta un cookie che appartiene al dominio della pubblicità (ad.foxytracking.com). Quindi, l’utente visita un altro sito web, www.foo.com, che contiene anche un annuncio da ad.foxytracking.com/, e che stabilisce anche un cookie appartenente a quel dominio (ad.foxytracking.com). Alla fine, entrambi questi cookie saranno inviati al venditore quando si caricano le loro pubblicità o visitando il loro sito web. L’inserzionista può quindi utilizzare questi cookie per costruire una cronologia di navigazione degli utenti in tutti i siti che hanno gli annunci di questo inserzionista. La maggior parte dei moderni browser web contengono delle impostazioni di privacy che sono in grado di bloccare i cookie di terze parti.
Esistono molti altri tipi di cookie, se vuoi approfondire l’argomento puoi farlo qui
HTTPS
Icona del lucchetto di HTTPS seguita dall'inizio di un URL che usa HTTPS
Icona del lucchetto di HTTPS seguita dall'inizio di un URL che usa HTTPS
L’HyperText Transfer Protocol over Secure Socket Layer (HTTPS), (anche noto come HTTP over TLS, HTTP over SSL e HTTP Secure) è un protocollo per la comunicazione sicura attraverso una rete di computer utilizzato su reti TCP/IP quali internet. Consiste nella comunicazione tramite il protocollo HTTP (Hypertext Transfer Protocol) all’interno di una connessione criptata, dal Transport Layer Security (TLS) o dal suo predecessore, Secure Sockets Layer (SSL) (protocolli di livello 6). Come HTTP utilizza TCP ma generalmente sulla porta 443. I servizi aggiuntivi offerti dall’uso dei protocolli di cifratura sono:
- cifratura del traffico;
- verifica di integrità del traffico (la correzione degli errori è già offerta da TCP ma TLS protegge da malevoli modifiche fatte da terzi);
- autenticazione del server;
- autenticazione dell’utente (in realtà spesso non avviene).
HTTP non è criptato, quindi è vulnerabile alle intercettazioni e ad attacchi man-in-the-middle: gli attaccanti possono ottenere l’accesso ad account di siti web con informazioni sensibili, o modificare le pagine web per iniettare al loro interno dei malware o della pubblicità malevola. HTTPS è progettato per resistere a tali attacchi ed è considerato sicuro contro di essi (con eccezione delle versioni più obsolete e deprecate del protocollo SSL).
Le URL del protocollo HTTPS iniziano con https:// e utilizzano la porta 443 di default, mentre le URL HTTP cominciano con http:// e utilizzano la porta 80. Normalmente nei browser viene anche usata l’icona di un lucchetto per indicare che la connessione in corso è cifrata è che il server si è correttamente autenticato (si è sicuri dell’identità del server).
Per comprendere meglio le funzionalità offerte da HTTPS è necessario studiare il funzionamento di TLS nella sezione ad esso dedicata. è anche possibile approfondire l’argomento sulla pagina Wikipedia dedicata a HTTPS
FTP
File Transfer Protocol (FTP) (protocollo di trasferimento file), in informatica e nelle telecomunicazioni, è un protocollo di livello applicazioni per la trasmissione di dati tra host basato su TCP e con architettura di tipo client-server.
Il protocollo usa connessioni TCP distinte per trasferire i dati e per controllare i trasferimenti e richiede autenticazione del client tramite nome utente e password, sebbene il server possa essere configurato per connessioni anonime con credenziali fittizie. Dato che FTP trasmette in chiaro sia tali credenziali sia ogni altra comunicazione, e visto che non dispone di meccanismi di autenticazione del server presso il client, il protocollo è spesso reso sicuro utilizzando un sottostrato SSL/TLS e tale variante è chiamata FTPS. L’acronimo SFTP designa invece un altro protocollo che, pur essendo molto simile a quest’ultimo dal punto di vista funzionale, è alquanto diverso da quello tecnologico: SSH File Transfer Protocol.
Cenni storici
FTP è uno dei primi protocolli definiti della Rete Internet e ha subito una lunga evoluzione negli anni. La prima specifica, sviluppata presso il MIT, risale al 1971 (RFC-114). L’attuale specifica fa riferimento all’RFC-959.
Gli obiettivi principali di FTP descritti nella sua RFC ufficiale furono:
- Promuovere la condivisione di file (programmi o dati)
- Incoraggiare l’uso indiretto o implicito di computer remoti.
- Risolvere in maniera trasparente incompatibilità tra differenti sistemi di stoccaggio file tra host.
- Trasferire dati in maniera affidabile ed efficiente.
Descrizione
FTP_model.png
Dove:
- PI (protocol interpreter) è l’interprete del protocollo, utilizzato da client (User-PI) e server (Server-PI) per lo scambio di comandi e risposte. In gergo comune ci si riferisce a esso come “canale comandi”.
- DTP (data transfer process) è il processo di trasferimento dati, utilizzato da client (User-DTP) e server (Server-DTP) per lo scambio di dati. In gergo comune ci si riferisce a esso come “canale dati”.
FTP, a differenza di altri protocolli come per esempio HTTP, utilizza due connessioni separate per gestire comandi e dati. Un server FTP generalmente rimane in ascolto sulla porta 21 TCP a cui si connette il client. La connessione da parte del client determina l’inizializzazione del canale comandi attraverso il quale client e server si scambiano comandi e risposte. Lo scambio effettivo di dati (come per esempio un file) richiede l’apertura del canale dati, che può essere di due tipi.
In un canale dati di tipo attivo il client apre una porta solitamente casuale, tramite il canale comandi rende noto il numero di tale porta al server e attende che si connetta. Una volta che il server ha attivato la connessione dati al client FTP, quest’ultimo effettua il binding della porta sorgente alla porta 20 del server FTP. A tale scopo possono venire impiegati i comandi PORT o EPRT, a seconda del protocollo di rete utilizzato (in genere IPv4 o IPv6).
In un canale dati di tipo passivo il server apre una porta solitamente casuale (superiore alla 1023), tramite il canale comandi rende noto il numero di tale porta al client e attende che si connetta. A tale scopo possono venire impiegati i comandi PASV o EPSV, a seconda del protocollo di rete utilizzato (in genere IPv4 o IPv6).
Sia il canale comandi, sia il canale dati sono delle connessioni TCP; FTP crea un nuovo canale dati per ogni file trasferito all’interno della sessione utente, mentre il canale comandi rimane aperto per l’intera durata della sessione utente, in altre parole il canale comandi è persistente mentre il canale dati è non persistente.
Un server FTP offre svariate funzioni che permettono al client di interagire con il suo filesystem e i file che lo popolano, tra cui:
Download/upload di file. Resume di trasferimenti interrotti. Rimozione e rinomina di file. Creazione di directory. Navigazione tra directory. FTP fornisce inoltre un sistema di autenticazione in chiaro (non criptato) degli accessi. Il client che si connette potrebbe dover fornire delle credenziali a seconda delle quali gli saranno assegnati determinati privilegi per poter operare sul filesystem. L’autenticazione cosiddetta “anonima” prevede che il client non specifichi nessuna password di accesso e che lo stesso abbia privilegi che sono generalmente di “sola lettura”.
Comandi
Lista dei comandi definiti nella RFC-959.
| Nome | Comando | Parametri | Descrizione |
|---|---|---|---|
| Abort | ABOR | Interrompe trasferimento dati. | |
| Account | ACCT | <account-information> | Informazioni account (raramente usato). |
| Allocate | ALLO | <decimal-integer> | Alloca spazio sufficiente per ricevere un file (raramente usato). |
| Append (with create) | APPE | <pathname> | Appende dati ad un file esistente. |
| Change to parent directory | CDUP | Va alla parent directory. | |
| Change working directory | CWD | <pathname> | Cambia directory corrente. |
| Delete | DELE | <pathname> | Cancella file. |
| Help | HELP | <command> | Ritorna la lista dei comandi accettati dal server. Con argomento fornisce spiegazioni riguardo al comando specificato. |
| List | LIST | <pathname> | Lista il contenuto di una directory o le proprietà di un singolo file. |
| Trasfer mode | MODE | <mode-type> | Imposta la modalità di trasferimento (S=stream, B=block, C=compressed). |
| Make directory | MKD | <pathname> | Crea directory. |
| Name list | NLST | <pathname> | Ritorna il nome dei file della directory specificata. |
| Noop | NOOP | Non fa nulla (usato prevalentemente per prevenire disconnessioni per inattività prolungata). | |
| Password | PASS | <password> | Specifica la password dell’utente. |
| Passive | PASV | Inizializza connessione dati passiva. | |
| Data port | PORT | <host-port> | Inizializza connessione dati attiva. |
| Print working directory | PWD | Ritorna nome della directory corrente. | |
| Logout | QUIT | Disconnette. Se un trasferimento è ancora in corso attende che termini prima di chiudere la sessione. | |
| Reinitialize | REIN | Effettua il log-off dell’utente loggato. | |
| Restart | REST | <marker> | Riprende il trasferimento dall’offset indicato. |
| Retrieve | RETR | <pathname> | Preleva file (da server a client). |
| Remove directory | RMD | <pathname> | Rimuove directory. |
| Rename from | RNFR | <pathname> | Rinomina (sorgente). |
| Rename to | RNTO | <pathname> | Rinomina (destinazione). |
| Site parameters | SITE | <command> | Manda comando specifico per il server (non standardizzato; varia tra implementazioni). |
| Structure mount | SMNT | <pathname> | Monta struttura (raramente usato). |
| Status | STAT | <pathname> | Ritorna statistiche riguardo al server. Con argomento lista il contenuto di una directory utilizzando il canale comandi. |
| Store | STOR | <pathname> | Spedisce un file (da client a server). |
| Store unique | STOU | <pathname> | Spedisce un file (da client a server) utilizzando un nome univoco. |
| File structure | STRU | <structure-code> | Imposta la struttura dati (F=file, R=record, P=page). Praticamente inutilizzato. Il valore di default è F. |
| System | SYST | Ritorna tipo di sistema operativo. | |
| Representation type | TYPE | <type> | Imposta la modalità di trasferimento (A=ASCII, E=EBCDIC, I=Binary, L=Local). Il valore di default è A. EBCDIC e Local sono raramente usati (esempio: unicamente su sistemi mainframe). |
| User Name | USER | <username> | Specifica nome utente. |
Codici di risposta
- 1xx: Risposta positiva preliminare. L’azione richiesta è incominciata ma ci sarà un’altra risposta a indicare che essa è effettivamente completata.
- 2xx: Risposta positiva definitiva. L’azione richiesta è completata. Il client può ora mandare altri comandi.
- 3xx: Risposta positiva intermedia. Il comando è stato accettato ma è necessario mandarne un secondo affinché la richiesta sia completata definitivamente.
- 4xx: Risposta negativa temporanea. Il comando non è andato a buon fine ma potrebbe funzionare in un secondo momento.
- 5xx: Risposta negativa definitiva. Il comando non è andato a buon fine e il client non dovrebbe più ripeterlo.
- x0x: Errore di sintassi.
- x1x: Risposta a una richiesta informativa.
- x2x: Risposta relativa alla connessione.
- x3x: Risposta relativa all’account e/o ai permessi.
- x4x: Non meglio specificato.
- x5x: Risposta relativa al file-system.
Problemi relativi alla sicurezza
La specifica originale di FTP non prevede alcuna cifratura per i dati scambiati tra client e server. Questo comprende nomi utenti, password, comandi, codici di risposta e file trasferiti i quali possono essere “sniffati” o visionati da malintenzionati in determinate situazioni (esempio: ambienti intranet).
Il problema è comune a diversi altri protocolli utilizzati prima della diffusione di SSL quali HTTP, TELNET e SMTP. Per ovviare al problema è stata definita una nuova specifica che aggiunge al protocollo FTP originale un layer di cifratura SSL/TLS più una nuova serie di comandi e codici di risposta. Il protocollo prende il nome di FTPS ed è definito nella RFC-4217. Da non confondersi con SFTP che è comunque una valida alternativa per ovviare al problema descritto.
Applicazioni che utilizzano FTP
FileZilla, Fire Downloader, JDownloader sono alcuni dei tanti gestori di download che permettono di trasferire i dati mediante connessione FTP.
Tuttavia nei sistemi operativi, in genere, si può effettuare l’accesso anche tramite riga di comando.
Server FTP
Alcuni server FTP popolari sono:
- FileZilla Server (Windows e Linux)
- Titan FTP Server (Windows)
- Pure-FTPd (Unix)
- VsFTPd (Unix)
- ProFTPd (Unix)
Posta elettronica
La posta elettronica, in inglese e-mail (abbreviazione di electronic mail), è un servizio Internet grazie al quale ogni utente abilitato può inviare e ricevere dei messaggi utilizzando un computer o altro dispositivo elettronico (come palmare, smartphone, tablet) connesso in rete attraverso un proprio account di posta registrato presso un fornitore del servizio.
È uno dei servizi Internet più conosciuti e utilizzati assieme alla navigazione web e la sua nascita risale al 1971, quando Ray Tomlinson installò su ARPANET un sistema in grado di scambiare messaggi fra le varie università, ma chi ne ha realmente definito il funzionamento fu Jon Postel.
Rappresenta la controparte digitale ed elettronica della posta ordinaria e cartacea. A differenza di quest’ultima, il ritardo con cui arriva dal mittente al destinatario è normalmente di pochi secondi/minuti, anche se vi sono delle eccezioni che ritardano il servizio fino a qualche ora. Per questo in generale di fatto ha rappresentato una rivoluzione nel modo di inviare e ricevere posta con la possibilità di allegare qualsiasi tipo di documento e immagini digitali entro certi limiti di dimensioni in byte.
Modello di servizio
Scopo del servizio di posta elettronica è il trasferimento di messaggi da un utente a un altro attraverso un sistema di comunicazione dati che coinvolge i client agli estremi (attraverso opportuni software di posta elettronica) e dei server di posta attivi presso i rispettivi fornitori del servizio come nodi di raccolta/smistamento dei messaggi interni alla rete.
Ciascun utente può possedere una o più caselle di posta elettronica, sulle quali riceve messaggi che vengono conservati. Quando lo desidera, l’utente può consultare il contenuto della sua casella, organizzarlo e inviare messaggi a uno o più utenti.
L’accesso alla casella di posta elettronica è normalmente controllato da una password o da altre forme di autenticazione.
La modalità di accesso al servizio è quindi asincrona, ovvero per la trasmissione di un messaggio non è necessario che mittente e destinatario siano contemporaneamente attivi o collegati.
La consegna al destinatario dei messaggi inviati non è garantita. Nel caso un server SMTP non riesca a consegnare un messaggio ricevuto, tenta normalmente di inviare una notifica al mittente per avvisarlo della mancata consegna, ma anche questa notifica è a sua volta un messaggio di posta elettronica (generato automaticamente dal server), e quindi la sua consegna non è garantita (se il problema è relativo all’apparecchio usato dal mittente non sarà possibile effettuarla).
Il mittente può anche richiedere una conferma di consegna o di lettura dei messaggi inviati, però il destinatario è normalmente in grado di decidere se vuole inviare o meno tale conferma. Il significato della conferma di lettura può essere ambiguo, in quanto aver visualizzato un messaggio per pochi secondi in un client non significa averlo letto, compreso o averne condiviso il contenuto.
Indirizzi di posta elettronica
A ciascuna casella sono associati uno o più indirizzi di posta elettronica necessari per identificare il destinatario. Questi hanno la forma nomeutente@dominio, dove nomeutente è un nome scelto dall’utente o dall’amministratore del server, che identifica in maniera univoca un utente (o un gruppo di utenti), e dominio è un nome DNS.
L’indirizzo di posta elettronica può contenere qualsiasi carattere alfabetico e numerico (escluse le vocali accentate) e alcuni simboli come il trattino basso (_) e il punto (.). Molto spesso può tornare utile agli utenti usufruire dei servizi di reindirizzamento, utilizzati per inoltrare automaticamente tutti i messaggi che arrivano su una casella di posta elettronica verso un’altra di loro scelta, in modo che al momento della consultazione non si debba accedere a tutte le caselle di posta elettronica di cui si è in possesso ma sia sufficiente controllarne una.
Esempio di indirizzo elettronico: test@esempio.com
Architettura del sistema di posta elettronica
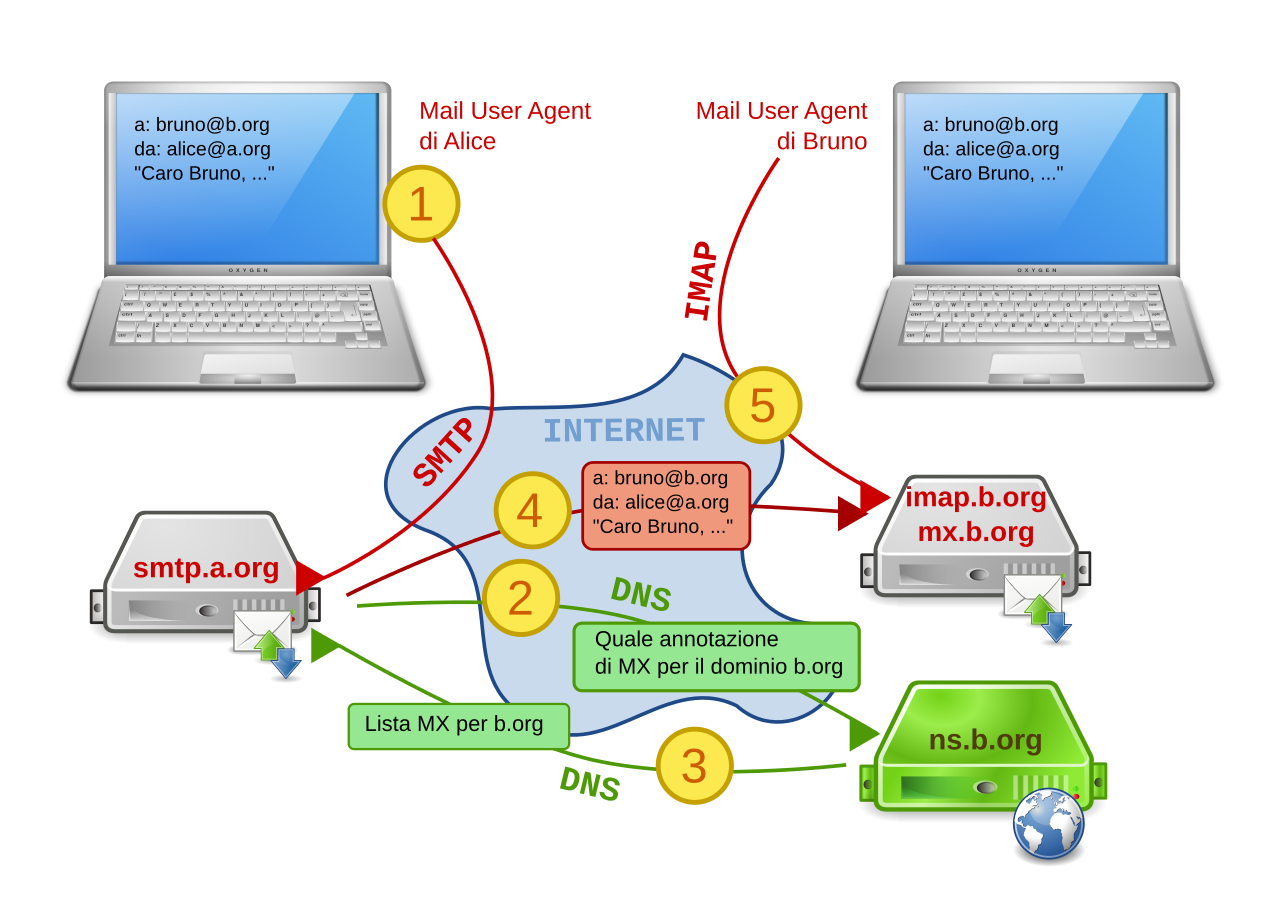
Schema di funzionamento del servizio di posta elettronica
Schema di funzionamento del servizio di posta elettronica
- i client (detti in gergo MUA, Mail User Agent), utilizzati per accedere a una casella di posta elettronica e per inviare messaggi;
- i server, che svolgono due funzioni fondamentali:
- immagazzinare i messaggi per uno o più utenti nella rispettiva casella di posta o mailbox (detti in gergo MS, Message Store);
- ricevere i messaggi in arrivo e in partenza e smistarli (detti in gergo MTA, mail transfer agent).
I protocolli tipicamente impiegati per lo scambio di messaggi di posta elettronica sono il SMTP, usato per l’invio, la ricezione e l’inoltro dei messaggi tra server, il POP e l’IMAP, usati per la ricezione e consultazione dei messaggi da parte degli utenti.
I client richiedono la configurazione dei server da contattare, e sono quindi adatti principalmente a computer usati regolarmente. È anche molto diffusa la possibilità di consultare una casella di posta elettronica attraverso il web (Webmail).
POP3s, SMTPs, IMAPs (e HTTPs) sono le versioni cifrate dei comuni protocolli di posta elettronica. Vari servizi di gestione della posta offrono la possibilità di una connessione cifrata con il protocollo Secure Sockets Layer (SSL, superato da TLS), inserendo nel programma client (es. Outlook Express) un parametro di posta in arrivo/posta in uscita (es. pops.[provider].it e smtps.[provider].it) oppure scegliendo una porta predefinita e spuntando le opzioni per la connessione SSL e l’autenticazione sicura.
SMTP - Simple Mail Transfer Protocol
Simple Mail Transfer Protocol (SMTP) è un protocollo standard per la trasmissione di email. Inizialmente proposto nella RFC 788 nel 1981, poi aggiornato con RFC 821 nel 1982 ed ulteriormente modificato nel 2008 con l’introduzione di extended SMTP (RFC 1869 e RFC 5321), che è il protocollo attualmente in uso.
Anche se i server di posta elettronica utilizzano SMTP per inviare e ricevere mail, i client mail a livello utente utilizzano SMTP solo per inviare il messaggio al server mail, il quale si occupa dell’invio del messaggio stesso. Per recuperare i messaggi, le applicazioni client usano solitamente protocolli come IMAP o POP3.
La comunicazione tra i server mail utilizza il protocollo TCP sulla porta 25. I client mail, tuttavia, spesso inviano le mail in uscita al server sulla porta 587. Anche se deprecata, i provider mail e alcuni produttori come Apple, permettono ancora l’uso della porta non standard 465 per questa operazione.
È possibile rendere sicura una connessione SMTP con TLS, nota come SMTPS.
Anche se sistemi proprietari (come Microsoft Exchange e IBM Notes) e sistemi webmail (come Outlook.com, Gmail e Yahoo! Mail) utilizzano protocolli non standard per accedere alla mail box dell’account del rispettivo server mail, tutti utilizzano SMTP, per l’invio e la ricezione di mail, al di fuori dei loro sistemi.
Non entreremo nei dettagli tecnici di questo protocollo che puoi approfondire qui
POP - Post Office Protocol
Il Post Office Protocol (detto anche POP) è un protocollo di livello applicativo di tipo client-server che ha il compito di permettere, mediante autenticazione, l’accesso da parte del client ad un account di posta elettronica presente su un host server e scaricare le e-mail dell’account stesso. Il protocollo per inviare posta è invece il protocollo SMTP.
Il POP (nella versione 3 detta comunemente POP3) rimane in attesa sulla porta 110 del server (di default, ma può anche essere diversa) per una connessione TCP da parte di un client.
I messaggi di posta elettronica, per essere letti, devono essere scaricati sul computer (questa è una notevole differenza rispetto all’IMAP), anche se è possibile lasciarne una copia sull’host. In pratica, il client, attraverso un account configurato POP, accede al server remoto e salva in locale i messaggi (definitivamente e non, come fa il protocollo IMAP, in una sorta di cache).
Anche con il protocollo POP3 si può impostare la cifratura, per evitare che le password utilizzate per l’autenticazione fra server e client passino “in chiaro”. L’estensione APOP utilizza MD5 come framework.
Oltre che con un classico client, un account di posta in entrata con protocollo POP può essere configurato in qualsiasi applicazione software che possa ricevere posta elettronica.
IMAP - Internet Message Access Protocol
L’Internet Message Access Protocol (IMAP), a volte anche chiamato Interactive Mail Access Protocol, è un protocollo di comunicazione per la ricezione di e-mail da parte del client.
Il significato “Interactive Mail Access Protocol” è stato valido fino alla versione 3, dalla quarta in poi è cambiato in “Internet Message Access Protocol”. L’attuale versione è la “4 (revisione 1)”.
Il protocollo è stato inventato da Mark Crispin nel 1986 come alternativa più moderna all’utilizzatissimo POP.
La porta predefinita del demone IMAP sull’host è la 143. Se si utilizza una connessione sicura tramite SSL, allora la porta è la 993.
Oltre che con un classico client, un account di posta in entrata con protocollo IMAP può essere configurato in qualsiasi applicazione software che possa ricevere posta elettronica.
Differenze tra IMAP e POP
Entrambi i protocolli permettono ad un client (programma di posta elettronica oppure servizio di webmail) di accedere, leggere e cancellare le e-mail da un server, ma con alcune differenze. Con entrambi i protocolli, il client scarica la posta direttamente sul PC, eventualmente cancellandola dal server, ma è altresì possibile conservare copia delle proprie e-mail sul server (opzione da selezionare in fase di configurazione), e scaricarle in un secondo momento da altri computer. IMAP, a differenza di POP, permette procedure complesse di sincronizzazione. Ecco un elenco delle caratteristiche dell’IMAP ma non del POP:
- Accesso alla posta sia online che off-line
Quando si utilizza il POP3, il client si connette per scaricare i nuovi messaggi e poi si disconnette. Con l’IMAP il client rimane connesso (in gergo IT “rimane in ascolto”) e risponde alle richieste che l’utente fa attraverso l’interfaccia; questo permette di risparmiare tempo se ci sono messaggi di grandi dimensioni. POP3 salva in locale i messaggi, IMAP li lascia sul server e li memorizza temporaneamente nella cache (sebbene si possa poi configurare il client perché crei un file dati archiviato in locale, ad esempio nel formato pst). - Più utenti possono utilizzare la stessa casella di posta
Il protocollo POP assume che un solo client (utente) sia connesso ad una determinata mailbox (casella di posta), quella che gli è stata assegnata. Al contrario l’IMAP4 permette connessioni simultanee alla stessa mailbox, fornendo meccanismi per controllare i cambiamenti apportati da ogni dispositivo/client di posta con il quale si utilizza l’account. - Supporto all’accesso a singole parti MIME di un messaggio
La maggior parte delle e-mail sono trasmesse nel formato MIME, che permette una struttura ad albero del messaggio, dove ogni ramo è un contenuto diverso (intestazioni, allegati o parti di esso, messaggio in un dato formato, eccetera). Il protocollo IMAP4 permette di scaricare una singola parte MIME o addirittura sezioni delle parti, per avere un’anteprima del messaggio o per scaricare una mail senza i file allegati. - Sincronizzazione
Con IMAP è possibile configurare il client di posta con regole di sincronizzazione rispetto ai server, potendo operare per singola cartella in maniera granulare e con diverse opzioni. - Sottoscrizione delle cartelle IMAP
Il protocollo è sviluppato secondo un framework che permette ad un client di posta di sottoscrivere le cartelle prescelte. Cartella “sottoscritta” significa cartella IMAP registrata nell’albero delle cartelle del client di posta e/o visualizzabile nella relativa gerarchia [1]. L’operazione è eseguita tramite query e successiva scelta di quale singola cartelle sottoscrivere. Solitamente, il client poi permette di visualizzare nella gerarchia di cartelle solo quelle sottoscritte o tutte. Tra le altre cose la sottoscrizione permette di condividere una cartella tra dispositivi/client/utenti diversi. La sottoscrizione è un’operazione di configurazione con il server di posta necessaria per poter visualizzare le cartelle IMAP e sincronizzarle con il server[. Qualora una cartella IMAP sottoscritta abbia raggiunto dimensione enormi, è possibile annullare la sottoscrizione in modo da aumentare la velocità di sincronizzazione con il server. - Supporto per attributi dei messaggi tenuti dal server.
Attraverso l’uso di attributi, tenuti sul server, definiti nel protocollo IMAP4, ogni singolo client può tenere traccia di ogni messaggio, per esempio per sapere se è già stato letto o se ha avuto una risposta. - Accesso a molteplici caselle di posta sul server
Alcuni utenti, con il protocollo IMAP4, possono creare, modificare o cancellare mailbox (di solito associate a cartelle) sul server. Inoltre, questa gestione delle mailbox, permette di avere cartelle condivise tra utenti diversi. - Possibilità di fare ricerche sul server
L’IMAP4 permette al client di chiedere al server quali messaggi soddisfano un certo criterio, per fare, per esempio, delle ricerche sui messaggi senza doverli scaricare tutti. - Supporto di un meccanismo per la definizione di estensioni
Nelle specifiche dell’IMAP è descritto come un server può far sapere agli utenti se ha delle funzionalità extra. Molte estensioni dell’IMAP sono molto diffuse, ad esempio l’IMAP Idle, ovvero la funzione del protocollo IMAP descritto nella RFC 2177 che consente a un client di indicare al server che è pronto ad accettare notifiche in tempo reale. Questa caratteristica permette quindi all’utente di ricevere dal server ogni modifica che avviene nella casella e-mail, senza il bisogno di premere ogni volta “Invia/Ricevi”.
Dati i molteplici vantaggi introdotti dal protocollo IMAP, il protocollo POP sta cadendo in disuso.
Messaggi di posta elettronica
Busta
Per busta si intendono le informazioni a corredo del messaggio che vengono scambiate tra server attraverso il protocollo SMTP, principalmente gli indirizzi di posta elettronica del mittente e dei destinatari. Queste informazioni normalmente corrispondono a quelle che è possibile ritrovare nelle intestazioni, ma possono esserci delle differenze.
Intestazioni
Le intestazioni sono informazioni di servizio che servono a controllare l’invio del messaggio, o a tener traccia delle manipolazioni che subisce. Ciascuna intestazione è costituita da una riga di testo, con un nome seguito dal carattere ‘:’ e dal corrispondente valore.
Alcune di queste vengono definite direttamente dall’utente. Tra le principali si possono citare:
- Oggetto: dovrebbe contenere una breve descrizione dell’oggetto del messaggio. È considerata buona educazione utilizzare questo campo per aiutare il destinatario a capire il contenuto del messaggio.
- Da: contiene l’indirizzo di posta elettronica del mittente.
- A: contiene gli indirizzi di posta elettronica dei destinatari principali.
- Cc: contiene gli indirizzi di posta elettronica dei destinatari in copia conoscenza.
- Ccn: contiene gli indirizzi di posta elettronica dei destinatari in copia conoscenza nascosta, ovvero destinatari che riceveranno il messaggio ma il cui indirizzo non apparirà tra i destinatari. Questa è in realtà una pseudo-intestazione, in quanto è visibile solo al mittente del messaggio, e per definizione non viene riportata nei messaggi inviati ai destinatari.
- Rispondi a: contiene l’indirizzo di posta elettronica al quale devono essere inviate le eventuali risposte al messaggio, se diverso da quello del mittente.
- Data: contiene la data e l’ora in cui il messaggio è stato scritto. Nota: è considerata cattiva educazione anche la pratica di inviare messaggi a un grande numero di destinatari e, in maniera particolare, se contengono allegati in formato proprietario che non tutti i destinatari potrebbero essere in grado di leggere, come Microsoft Word. Qualora si dovesse inviare un messaggio a un certo numero di destinatari (≥2) dei quali non si è certi che intendano rendere noto agli altri destinatari il proprio indirizzo elettronico (ciò che accade normalmente), è considerato netiquette inviare a sé stessi il messaggio (porre il proprio indirizzo come destinatario) e inserire in ccn (copia conoscenza nascosta) gli altri destinatari. Infatti i destinatari-ccn non si vedono reciprocamente.
Intestazioni di servizio
Altre intestazioni vengono aggiunte dai programmi che manipolano il messaggio.
La più importante è Ricevuti:, che viene aggiunta da ciascun server SMTP che manipola il messaggio, indicando da quale indirizzo IP il messaggio è stato ricevuto, a che ora, e altre informazioni utili a tracciarne il percorso.
Altre intestazioni segnalano ad esempio che il messaggio è stato valutato da qualche tipo di filtro automatico antivirus o antispam, e la valutazione espressa dal filtro.
Il Message-ID: (Identificativo del messaggio) è un codice costruito dal client su cui il messaggio è stato composto, che dovrebbe permettere di identificare univocamente un messaggio.
Corpo e allegati
Il corpo del messaggio è composto dal contenuto informativo che il mittente vuol comunicare ai destinatari.
Esso era originalmente composto di testo semplice. In seguito è stata introdotta la possibilità di inserire dei file in un messaggio di posta elettronica (allegati), ad esempio per inviare immagini o documenti. Per fare questo il client di posta del mittente utilizza la codifica MIME (o la più desueta UUencode).
Gli allegati vengono utilizzati anche per comporre un messaggio di posta elettronica in formato HTML, generalmente per ottenere una più gradevole visualizzazione dello stesso. Questa pratica non è molto apprezzata dai puristi di Internet, in quanto aumenta notevolmente la dimensione dei messaggi e, inoltre, non tutti i client per la posta elettronica sono in grado di interpretare l’HTML.
Dato che la banda del canale (Internet) e la dimensione della casella di posta elettronica (sul server) non sono illimitate, è considerata cattiva educazione inviare messaggi di grosse dimensioni. Secondo la netiquette un messaggio di posta elettronica dovrebbe rimanere al di sotto di 50-100 kB. Per ridurre le dimensioni di un messaggio contenente allegati di grosse dimensioni, si possono inviare semplicemente gli URI degli allegati, rendendo questi ultimi reperibili in altro modo, ad esempio via FTP o HTTP. Inoltre, molti server impongono limiti massimi alla dimensione del messaggio da trasmettere, che devono essere presi in considerazione se si inviano messaggi di grosse dimensioni.
Abusi e attacchi
Il principale utilizzo improprio della posta elettronica è lo spam, l’invio massiccio a molti utenti di messaggi indesiderati, in genere di natura pubblicitaria-commerciale. Secondo alcune fonti, l’incidenza di questi messaggi raggiungerebbe i due terzi del traffico totale di posta elettronica.
Un altro fenomeno negativo è costituito dalle catene di sant’Antonio, messaggi che contengono informazioni allarmanti, promesse di facili guadagni o vere e proprie bufale, e invitano a inoltrare il messaggio ai propri conoscenti, finendo talvolta per circolare per mesi o per anni.
Esiste inoltre la possibilità di falsificare il nome e l’indirizzo del mittente visualizzati nel programma client del destinatario, inducendo l’utente a ritenere attendibile un messaggio del tutto falso. Questa vulnerabilità viene usata per costruire vere e proprie truffe o scherzi che si basano sulla fiducia che la maggior parte degli utenti erroneamente ripone nel «mittente» di un messaggio di posta elettronica. Anche i worm che si replicano per posta elettronica usano questo meccanismo, allo scopo di indurre gli utenti a provare interesse o a prestare fiducia in un messaggio, in modo che lo aprano ed eventualmente installino allegati infetti.
Le email possono essere vittima di alcuni attacchi hacker:
-
Spoofing e phishing
In un caso di spoofing di e-mail, un criminale informatico invia a un utente un’e-mail fingendo di essere qualcuno che l’utente conosce. Risulta molto difficile da risalire al suo vero mittente.
Viene utilizzato dai criminali informatici per ingannare gli utenti e ottenere informazioni sensibili come conti bancari o numeri di previdenza sociale. -
Domain squatting
Il Domain Squatting consiste nel registrare, vendere o utilizzare un nome di dominio con l’intento di trarre profitto dal marchio di qualcun altro. Pertanto le aziende o i loro clienti possono essere vittime di attacchi di Domain Squatting. -
Spear phishing
Mentre le campagne di phishing regolari perseguono un gran numero di obiettivi a rendimento relativamente basso, lo spear phishing mira a obiettivi specifici utilizzando messaggi di posta elettronica appositamente creati per la vittima designata. Per questi attacchi gli hacker usano servizi come WinZip, Box, Dropbox, OneDrive o Google Drive. -
File dannosi
Quando un contenuto dannoso nell’allegato e-mail raggiunge l’utente potrebbe infettare l’intero sistema del computer (o lo smartphone o il tablet) e la rete. -
Ransomware
Una volta che qualcuno viene infettato via mail deve essere pagato un riscatto per tutti i dati crittografati[7]. -
Configurazioni errate
Una configurazione errata nel servizio di posta elettronica può causare l’invio di posta elettronica senza autenticazione. Ad esempio un hacker si connette al servizio di posta elettronica di una vittima senza autenticazione e inviare un’e-mail ai suoi contatti memorizzati nella rubrica. -
Exploit Kit
Software in grado di realizzare attacchi informatici di tipo web-based con l’obiettivo di distribuire malware o altre componenti malevole anche attraverso le email. -
Attacchi BEC (Business Email Compromise)
Una forma particolare di phishing che sfrutta sofisticate tecniche di ingegneria sociale per ottenere l’accesso a informazioni personali o riservate, e specificamente informazioni di rilevante valore economico e commerciale. In genere un attacco prende di mira ruoli specifici dei dipendenti all’interno di un’organizzazione inviando una o più e-mail di spoofing che rappresentano in modo fraudolento un collega senior (CEO o simile) o un cliente fidato. Conosciuto anche come “Whaling”. -
Email Injection
L’Email Injection è una vulnerabilità di sicurezza che può verificarsi nelle applicazioni di posta elettronica. È l’equivalente e-mail dell’HTTP Header Injection. Come gli attacchi SQL injection, questa vulnerabilità appartiene a una classe generale di vulnerabilità che si verifica quando un linguaggio di programmazione è incorporato in un altro.
Posta elettronica certificata
La Posta elettronica certificata è un servizio di posta elettronica erogato nel solo Stato italiano che permette di ottenere la garanzia legale del ricevimento del messaggio da parte del destinatario e della integrità del messaggio ricevuto. Non prevede invece la segretezza del contenuto del messaggio o la certificazione del mittente, e pone parecchi problemi nell’uso con soggetti esteri.
In Italia l’invio di un messaggio di posta elettronica certificato, nelle forme stabilite dalla normativa vigente (in particolare il D.P.R. n. 68/2005 e il D. Lgs. n. 82/2005 Codice dell’amministrazione digitale), è equiparato a tutti gli effetti di legge alla spedizione di una raccomandata cartacea con avviso di ricevimento. Ai fini della legge, il messaggio si considera consegnato al destinatario quando è accessibile nella sua casella di posta. Dal 29 novembre 2011 tutte le aziende devono disporre e comunicare alla Camera di Commercio il proprio indirizzo di Posta Elettronica Certificata.
Il meccanismo consiste nel fatto che il gestore di posta elettronica certificata, nel momento in cui prende a carico il messaggio di posta elettronica del mittente, invia a esso una ricevuta di accettazione, che certifica l’avvenuto invio. Nel momento invece in cui il gestore deposita il messaggio nella casella del destinatario, invia al mittente una ricevuta di consegna che certifica l’avvenuta ricezione. Sia la ricevuta di accettazione sia la ricevuta di consegna sono in formato elettronico, e a esse è apposta la firma digitale del gestore.
Se il gestore di posta elettronica certificata del mittente è diverso dal gestore del destinatario, si ha un passaggio ulteriore: il gestore del destinatario, nel momento in cui riceve la mail dal gestore del mittente, emette una ricevuta di presa a carico, in formato elettronico, a cui appone la propria firma digitale. Se il gestore di posta elettronica non è in grado di depositare la mail nella casella del destinatario, invia una ricevuta di mancata consegna. I gestori di posta certificata hanno l’obbligo di non accettare le mail contenenti virus.
I gestori di posta elettronica certificata sono soggetti privati che devono possedere una pluralità di requisiti stabiliti dalla legge (devono, per esempio, possedere gli stessi requisiti di onorabilità previsti per l’attività bancaria, e avere un capitale sociale non inferiore a 1 milione di euro), e possono operare solo se sono autorizzati dal CNIPA, il Centro Nazionale per l’Informatica nella Pubblica Amministrazione.
Le pubbliche amministrazioni possono essere gestori di posta elettronica certificata, ma in tal caso gli indirizzi rilasciati hanno validità solo limitatamente agli scambi di mail fra il titolare dell’indirizzo e l’Amministrazione che lo ha rilasciato.
Email HTML
L’e-mail HTML è l’uso di un sottoinsieme di HTML per fornire funzionalità di formattazione e markup semantico nelle e-mail che non sono disponibili con testo normale. Il testo è disposto per adattarsi alla larghezza della finestra di visualizzazione, invece di spezzare uniformemente ogni riga a 78 caratteri (definito in RFC 5322, che era necessario sui terminali più vecchi). Consente l’inclusione in linea di immagini, tabelle, diagrammi o formule matematiche come immagini, che sono altrimenti difficili da trasmettere (tipicamente usando l’arte ASCII).
La maggior parte dei client di posta elettronica supportano la posta elettronica HTML e molti lo utilizzano per impostazione predefinita. Molti di questi client includono sia un editor GUI per la composizione di messaggi di posta elettronica HTML sia un motore di rendering per la visualizzazione di messaggi di posta elettronica HTML ricevuti.
La struttura va fatta con il tag TABLE e la formattazione con il tag in linea STYLE poiché non è possibile utilizzare i CSS.
Inoltre è possibile inserire nel layout di una email HTML dei video attraverso l’apposito tag.
Molti permettono di aprire l’email HTML ricevuta nel browser attraverso un link, in caso la visualizzazione sul programma di posta sia scarsa.
Vulnerabilità
L’HTML consente di visualizzare un collegamento come testo arbitrario, in modo che, anziché visualizzare l’URL completo, un collegamento possa mostrarne solo una parte o semplicemente un nome di destinazione intuitivo. Questo può essere utilizzato negli attacchi di phishing, in cui gli utenti sono indotti a credere che un collegamento punti al sito Web di una fonte autorevole (come una banca), visitandolo e rivelando involontariamente dettagli personali (come i numeri di conto bancario) a un truffatore.
Se un’e-mail contiene bug (contenuto in linea da un server esterno, come un’immagine), il server può avvisare una terza parte che l’e-mail è stata aperta. Questo è un potenziale rischio per la privacy, poiché rivela che un indirizzo e-mail è reale (in modo che possa essere preso di mira in futuro) e rivela quando il messaggio è stato letto. Per questo motivo, tutti i moderni client di posta elettronica più diffusi (a partire dall’anno 2019) non caricano immagini esterne fino a quando non vengono richieste dall’utente.
Link e riferimenti esterni
- ISO/OSI su Wikipedia
- Incapsulamento su Wikipedia
- TCP/IP su Wikipedia
- Livello di trasporto su Wikipedia
- Porte su Wikipedia
- Socket su Wikipedia
- Elenco delle porte su Wikipedia in italiano e in inglese (più approfondito)
- TCP su Wikipedia
- UDP su Wikipedia
- Peer to Peer su Wikipedia
- TLS su Wikipedia
- URI su Wikipedia
- DNS su Wikipedia
- Articolo sui DNS pubblici
- HTTP su Wikipedia
- Cookies su Wikipedia
- HTTPS su Wikipedia
- FTP su Wikipedia
- Posta elettronica su Wikipedia
- SMTP su Wikipedia
- POP su Wikipedia
- IMAP su Wikipedia