Livello 3: Rete (Network Layer)
Obiettivo: rendere i livelli superiori indipendenti dai meccanismi e dalle tecnologie di trasmissione usate per la connessione e prendersi carico della consegna a destinazione dei pacchetti.
Indice
- Funzionalità
- Protocollo IP
- Protocollo ARP
- Router
- Link e riferimenti esterni
Funzionalità
Il livello di rete è responsabile di:
- routing: scelta ottimale del percorso di rete da utilizzare per garantire la consegna delle informazioni dal mittente al destinatario, scelta svolta dal router attraverso dei particolari algoritmi di Routing e tabelle di routing.
- conversione dei dati nel passaggio fra una rete ed un’altra con diverse caratteristiche, come il protocollo di rete utilizzato (internet-working). Deve, quindi:
- tradurre gli indirizzi di rete;
- valutare la necessità di frammentare i pacchetti dati se la nuova rete prevede una diversa dimensione dei pacchetti;
- valutare la necessità di gestire diversi protocolli attraverso l’impiego di gateway.
La sua unità dati fondamentale è il pacchetto.
Il protocollo di rete più usato è il protocollo IP (Internet Protocol) usato in tutte le reti TCP/IP. Lo studio di questo protocollo permetterà di comprendere nel dettaglio tutte le funzionalità normalmente offerte da questo livello.
Protocollo IP
Internet Protocol (IP), in telecomunicazioni e informatica, è un protocollo di rete, che si occupa di indirizzamento/instradamento, appartenente alla suite di protocolli Internet TCP/IP su cui è basato il funzionamento della rete Internet.
È un protocollo di interconnessione di reti (Inter-Networking Protocol), classificato al livello di rete (3) del modello ISO/OSI, nato per interconnettere reti eterogenee per tecnologia, prestazioni, gestione, pertanto implementato sopra altri protocolli di livello collegamento, come Ethernet o ATM. È un protocollo a pacchetti senza connessione e di tipo best effort, che non garantisce cioè alcuna forma di affidabilità della comunicazione in termini di controllo di errore, controllo di flusso e controllo di congestione, che può essere invece realizzata dai protocolli di trasporto di livello superiore (livello 4), come TCP.
Correntemente sono usate due versioni del protocollo IP, l’originaria versione 4 e la più recente versione 6, nata dall’esigenza di gestire meglio il crescente numero di dispositivi (host) connessi ad Internet.
Compiti e funzioni
Il principale compito di IP è l’Indirizzamento e l’instradamento (commutazione) tra sottoreti eterogenee, che a livello locale utilizzano invece un indirizzamento proprio, tipicamente basato sull’indirizzo fisico o indirizzo MAC e protocolli di livello datalink (2) del modello ISO-OSI (es. Ethernet, Token ring, Token bus). Per far ciò è necessario assegnare un nuovo piano di indirizzamento a cui tutte le sottoreti devono sottostare per poter comunicare e interoperare tra loro: tale piano è rappresentato proprio dal Protocollo IP. Questo comporta infatti:
- l’assegnazione a ciascun terminale che ne fa richiesta (cioè si connette alla rete Internet) di un nuovo diverso indirizzo, univocamente associato all’indirizzo MAC locale, detto Indirizzo IP (assegnato manualmente o automaticamente per mezzo del protocollo DHCP);
- la definizione delle modalità o procedure tese a individuare il percorso di rete per interconnettere due qualunque sottoreti durante una comunicazione tra host sorgente di una certa sottorete e host destinatario di un’altra sottorete, cui l’indirizzo IP appartiene. La conoscenza di questo percorso di rete comporta a sua volta l’assegnazione e la conoscenza dell’indirizzo IP a ciascun commutatore (router) che collega la rete dell’host emittente con quella dell’host destinatario, cioè quindi la conoscenza della sequenza di tutti i router di tutte le sottoreti da attraversare.
In sostanza dunque IP rappresenta la “colla” che unisce tra loro tutte le varie sottoreti eterogenee, a livello di indirizzamento\instradamento, permettendone il dialogo o scambio di informazioni tra loro cioè l’interlavoro (internetworking) o interoperabilità in fatto di trasmissione. Rimane invece compito delle singole sottoreti occuparsi di instradare al loro interno i pacchetti tramite i protocolli locali di livello 2. I pacchetti possono attraversare interamente una sottorete per dirigersi verso la successiva secondo le indicazioni del protocollo IP oppure, se si è già raggiunta la sottorete del destinatario, possono essere instradati verso l’Indirizzo MAC locale dell’host destinatario, risolvendo l’indirizzo IP dell’host in indirizzo MAC tramite protocollo ARP (Protocollo che permette di associare indirizzi MAC ad indirizzi IP). Sotto questo punto di vista (che coincide con la nascita e lo sviluppo storico di Internet) si parla comunemente di integrazione nell’architettura logico-protocollare delle sottoreti del protocollo IP.
In generale dunque l’instradamento in Internet può essere diretto (o locale) (direct forwarding) se deve essere attraversata una sola sottorete fisica cioè l’host destinatario fa parte della stessa sottorete dell’host sorgente oppure indiretto (indirect forwarding) se devono essere attraversate più di una sottorete ovvero se l’host destinatario non appartiene alla stessa sottorete dell’host sorgente. Per quanto detto precedentemente quest’ultimo tipo di indirizzamento altro non è che una successione di instradamenti diretti.
Anche se l’indirizzamento indiretto altro non è che una successione di instradamenti diretti tramite i protocolli locali di trasporto di livello 2, in generale operare un indirizzamento di livello 3 tramite i soli indirizzi MAC, pur essendo questi univoci per ciascun terminale host, non sarebbe stato possibile perché essi non danno vita ad un piano di indirizzamento gerarchico cioè gli indirizzi MAC, il cui assegnamento è pseudo-casuale, non sono raggruppabili in sottoreti con lo stesso prefisso identificativo come invece lo sono gli indirizzi Host_IP. In altri termini esisterebbero notevoli problemi di scalabilità nell’implementare tabelle di instradamento indicizzate non per identificativi di sottoreti (Net_ID), ma per ciascun indirizzo MAC esistente. Per capire meglio questo concetto è necessario comprendere struttura ed utilizzo degli indirizzi IP.
Indirizzo IP
Un indirizzo IP è un numero (sequenza di bit che varia di lunghezza in base alla versione del protocollo) che identifica univocamente un’interfaccia di un host connessa alla rete fisica. L’indirizzo IP è assegnato propriamente all’interfaccia (ad esempio una scheda di rete) e non all’host, perché è questa ad essere connessa alla rete. Un router, ad esempio, ha diverse interfacce e per ognuna occorre un indirizzo IP. Sarebbe quindi impreciso dire che un indirizzo IP identifica univocamente un host anche se in molti casi è vero.
Gli indirizzi IP sono indicati negli header dei pacchetti IP e sono essenziali per permettere l’instradamento dei pacchetti. Analogamente a quanto succede per un indirizzo stradale od un numero di telefono ci permettono di identificare univocamente sorgente e destinazione di una comunicazione.
L’indirizzo IP si compone di due parti: indicatore di rete (Net_ID) e indicatore di host (Host_ID); la parte Net_ID è assegnata all’ICANN che a sua volta delega organizzazioni regionali (Europa, Asia, ecc) che a loro volta delegano altre organizzazioni (per l’Italia GARR).
- La prima parte quindi identifica la rete, chiamata network o routing prefix (Net_ID) ed è utilizzato per l’instradamento a livello di sottoreti.
- La seconda parte invece identifica, all’interno della rete, l’host (o l’interfaccia in IPv6) e le eventuali sottoreti (Host_ID) ed è utilizzato per l’instradamento a livello locale dell’host una volta raggiunta la sottorete locale di destinazione, cui segue la traduzione o risoluzione in indirizzo MAC per l’effettiva consegna del pacchetto dati al destinatario con i protocolli di livello 2 della rete locale (che possono variare tra sottoreti diverse).
IPv4

Un esempio di indirizzo IPv4
Un esempio di indirizzo IPv4
L’indirizzo IPv4 è costituito da 32 bit (4 byte) suddiviso in 4 gruppi da 8 bit (1 byte), separati ciascuno da un punto (notazione dotted, es. 11001001.00100100.10101111.00001111). Ciascuno di questi 4 byte è poi convertito in formato decimale di più facile identificazione, che semplifica la lettura e la memorizzazione da parte di noi umani, (quindi ogni numero varia tra 0 e 255 essendo 28=256, ovvero le combinazioni disponibili ci dicono quanti numeri possiamo utilizzare in ogni gruppo identificato dal punto). Un esempio di indirizzo IPv4 è 172.16.254.1 che corrisponde a una notazione binaria.
Nello standard IPv4 (Internet Protocol versione 4), essendo costituito da 32 bit, le combinazioni utilizzabili sono 232 pari a circa 4 miliardi. All’inizio, 1981, sembravano tanti, tuttavia oggi sono pochi poiché se ognuno di noi ha diversi dispositivi connessi ad internet, questi avranno degli indirizzi IP univoci. Basti pensare che molte persone posseggono uno smartphone, un computer e una smart TV, quindi 3 indirizzi IP. Sono quindi state identificate due soluzioni: la separazione tra indirizzi privati e indirizzi pubblici, e il passaggio al protocollo IPv6 che utilizza indirizzi più lunghi (128 bit). Queste soluzioni saranno descritte nel dettaglio più avanti.
Il pacchetto
Per chi non si occupi direttamente della gestione dei pacchetti non è particolarmente rilevante conoscere in dettaglio la struttura del pacchetto IPv4 ma è bene almeno averne un’idea generale, per completezza è di seguito rappresentata e descritta.
L’header del pacchetto IPv4 consiste in 13 campi di cui 1 opzionale (segnalato nello schema con sfondo rosso) e chiamato con il nome di Options.
| + | Bits 0–3 | 4–7 | 8–15 | 16–18 | 19–31 | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | Version | Internet Header length | Type of Service (adesso DiffServ e ECN) | Total Length | ||||||||||||||||||||||||||||
| 32 | Identification | Flags | Fragment Offset | |||||||||||||||||||||||||||||
| 64 | Time to Live | Protocol | Header Checksum | |||||||||||||||||||||||||||||
| 96 | Source Address | |||||||||||||||||||||||||||||||
| 128 | Destination Address | |||||||||||||||||||||||||||||||
| 160 | Options (facoltativo) | |||||||||||||||||||||||||||||||
| 160 o 192+ | Data | |||||||||||||||||||||||||||||||
- Versione [4 bit] - Indica la versione del pacchetto IP: per IPv4, ha valore 4 (da qui il nome IPv4);
- Internet Header Length (IHL) [4 bit] - Indica la lunghezza (in word da 32 bit) dell’header del pacchetto IP ovvero l’offset del campo dati; tale lunghezza può variare da 5 word (20 byte) a 15 word (60 byte) a seconda della presenza e della lunghezza del campo facoltativo Options;
- Type of Service (TOS) [8 bit] - Nelle specifiche iniziali del protocollo (RFC 791), questi bit servivano all’host mittente per specificare il modo e in particolare la precedenza con cui l’host ricevente doveva trattare il datagramma:
- bit 0-2: Precedenza
- bit 3: Latenza (0 = normale, 1 = bassa)
- bit 4: Throughput (0 = normale, 1 = alto)
- bit 5: Affidabilità (0 = normale, 1 = alta)
- bit 6-7: Riservati per usi futuri
Ad esempio un host poteva scegliere una bassa latenza, mentre un altro preferire un’alta affidabilità. Nella pratica questo uso del campo TOS non ha preso largamente piede. Dopo molte sperimentazioni e ricerche, recentemente questi 8 bit sono stati ridefiniti ed hanno la funzione di Differentiated services (DiffServ) nell’IETF e Explicit Congestion Notification (ECN) codepoints (vedi RFC 3168), necessari per le nuove tecnologie basate sullo streaming dei dati in tempo reale, come per esempio il Voice over IP (VoIP) usato per lo scambio interattivo dei dati vocali;
- Total Length [16 bit] - Indica la dimensione (in byte) dell’intero pacchetto, comprendendo header e dati; tale lunghezza può variare da un minimo di 20 byte (header minimo e campo dati vuoto) ad un massimo di 65535 byte. In ogni momento, ad ogni host è richiesto di essere in grado di gestire datagrammi aventi una dimensione minima di 576 byte mentre sono autorizzati, se necessario, a frammentare datagrammi di dimensione maggiore;
- Identification [16 bit] - Utilizzato, come da specifiche iniziali, per identificare in modo univoco i vari frammenti in cui può essere stato “spezzato” un pacchetto IP. Alcune sperimentazioni successive hanno però suggerito di utilizzare questo campo per altri scopi, come aggiungere la funzionalità di tracciamento dei pacchetti;
- Flags [3 bit] - Bit utilizzati per il controllo del protocollo e della frammentazione dei datagrammi: Reserved - sempre settato a 0. Come pesce d’aprile, in RFC 3514 si è proposto di utilizzarlo come “Evil bit”; DF (Don’t Fragment) - se settato a 1 indica che il pacchetto non deve essere frammentato; se tale pacchetto non può essere inoltrato da un host senza essere frammentato, viene semplicemente scartato. Questo può risultare utile per “ispezionare” la capacità di gestione dei vari host del percorso di routing; MF (More Fragments) - se settato a 0 indica che il pacchetto è l’ultimo frammento o il solo frammento del pacchetto originario, pertanto tutti gli altri suoi frammenti hanno il bit MF settato a 1. Naturalmente, questo bit sarà sempre 0 anche in tutti i datagrammi che non sono stati frammentati.
- Fragment Offset [13 bit] - Indica l’offset (misurato in blocchi di 8 byte) di un particolare frammento relativamente all’inizio del pacchetto IP originale: il primo frammento ha offset 0. L’offset massimo risulta pertanto pari a {\displaystyle 2^{16}-8}{\displaystyle 2^{16}-8}65528 byte che, includendo l’header, potrebbe eccedere la dimensione massima di 65535 byte di un pacchetto IP;
- Time to live (TTL) [8 bit] - Indica il tempo di vita (time to live) del pacchetto, necessario per evitarne la persistenza indefinita sulla rete nel caso in cui non si riesca a recapitarlo al destinatario. Storicamente il TTL misurava i “secondi di vita” del pacchetto, mentre ora esso misura il numero di “salti” da nodo a nodo della rete: ogni router che riceve il pacchetto prima di inoltrarlo ne decrementa il TTL (modificando di conseguenza anche il campo Header Checksum), quando questo arriva a zero il pacchetto non viene più inoltrato ma scartato. Tipicamente, quando un pacchetto viene scartato per esaurimento del TTL, viene automaticamente inviato un messaggio ICMP al mittente del pacchetto, specificando il codice di Richiesta scaduta; la ricezione di questo messaggio ICMP è alla base del meccanismo di traceroute;
- Protocol [8 bit] - Indica il codice associato al protocollo utilizzato nel campo dati del pacchetto IP: per esempio al protocollo TCP è associato il codice 6, ad UDP il codice 17, mentre ad IPv6 è associato il codice 41. La lista dei codici dei vari protocolli, inizialmente definita in RFC 790, è mantenuta e gestita dalla Internet Assigned Numbers Authority.
- Header Checksum [16 bit] - È un campo usato per il controllo degli errori dell’header. Ad ogni hop, il checksum viene ricalcolato (secondo la definizione data in RFC 791) e confrontato con il valore di questo campo: se non c’è corrispondenza il pacchetto viene scartato. È da notare che non viene effettuato alcun controllo sulla presenza di errori nel campo Data deputandolo ai livelli superiori;
- Source address [32 bit] - Indica l’indirizzo IP associato all’host del mittente del pacchetto. Da notare che questo indirizzo potrebbe non essere quello del “vero” mittente nel caso di traduzioni mediante NAT. Infatti, qualora un host intermedio effettui questa traduzione, sostituisce l’indirizzo del mittente con uno proprio, premurandosi poi di ripristinare l’indirizzo originario su tutti i messaggi di risposta che gli arrivano destinati al mittente originario;
- Destination address [32 bit] - Indica l’indirizzo IP associato all’host del destinatario del pacchetto e segue le medesime regole del campo Source address;
- Options - Opzioni (facoltative e non molto usate) per usi più specifici del protocollo, come informazioni sui router; Si ricorda che il valore del campo IHL deve essere sufficientemente grande da includere anche tutte le opzioni e, nel caso queste siano più corte di una word, il padding necessario a completare i 32 bit. Inoltre, nel caso in cui la lista di opzioni non coincida con la fine dell’header, occorre aggiungere in coda ad essa un marcatore EOL (End of Options List). C’è da notare infine che, potendo causare problemi di sicurezza, l’uso delle opzioni LSSR e SSRR (Loose e Strict Source and Record Route) è scoraggiato e molti router bloccano i datagrammi che contengono queste opzioni.
Subnet Mask
La maschera di sottorete o subnet mask è una sequeza di bit lunga come gli indirizzi IP (quindi 32 bit in IPv4) che permette di separare Host_ID e Net_ID di un indirizzo IP. Per effettuare la separazione nelle due parti si effettua una operazione di AND logico tra indirizzo IP e subnet mask la quale ha tutti i bit corrispondenti al Net_ID con valore 1 e tutti i bit corrispondenti all’Host_ID con valore 0.
La subnet mask può essere rappresentata in diversi modi:
- sequenza di 1 e 0 che è il modo in cui è effettivamente memorizzata ed utilizzada dai computer ma è scomodo per gli esseri umani, ad esempio
11111111.11111111.11111111.11100000; - rappresentazione dotted decimal simile agli indirizzi IP, ad esempio 255.255.255.224 che corrisponde a
11111111.11111111.11111111.11100000 - rappresentazione CIDR che indica a fianco degli indirizzi IP il numero di bit a 1 della corrispondente subnet mask, ad esempio in
192.168.32.97/27la subnet mask è di nuovo11111111.11111111.11111111.11100000
Di seguito vediamo in pratica come viene utilizzata la subnet mask vista negli esempi precedenti.
Supponiamo che il protocollo IP del nostro computer sia configurato come segue:
- indirizzo IP:
192.168.32.97 - maschera di sottorete:
255.255.255.224
e che vogliamo spedire un pacchetto all’indirizzo IP 192.168.32.130;
Prima di tutto trasformiamo in notazione binaria gli indirizzi IP e la maschera di sottorete:
192.168.032.097 = 11000000.10101000.00100000.01100001
192.168.032.130 = 11000000.10101000.00100000.10000010
255.255.255.224 = 11111111.11111111.11111111.11100000
Allora il livello IP calcolerà per l’indirizzo sorgente:
11000000.10101000.00100000.01100001 AND (192.168.032.097)
11111111.11111111.11111111.11100000 = (255.255.255.224)
-------------------------------------
11000000.10101000.00100000.01100000 (192.168.032.096)
Ora ripetiamo l’operazione con l’IP di destinazione:
11000000.10101000.00100000.10000010 AND (192.168.032.130)
11111111.11111111.11111111.11100000 = (255.255.255.224)
-------------------------------------
11000000.10101000.00100000.10000000 (192.168.032.128)
I risultati 192.168.32.96 e 192.168.32.128 indicano due sottoreti differenti, e quindi le macchine appartengono a sottoreti differenti. I due indirizzi ottenuti inoltre non indicano alcun host ma identificano un’intera sottorete. Esistono due indirizzi particolari in ogni rete che non possono essere utilizzati da nessun host e sono:
- l’indirizzo di rete che è il primo indirizzo della rete, quello che presenta tutti 0 nell’Host_ID come nel caso dei due indirizzi ottenuti nell’esempio precedente:
192.168.32.96/27e192.168.32.128/27, questi indirizzi identificano le reti e non degli host; - l’indirizzo di broadcast che è l’ultimo indirizzo della rete, quello che presenta tutti 1 nell’Host_ID; questo indirizzo non è specifico di nessun host ma serve per indicare tutti gli host della rete (ad esempio in una comunicazione broadcast a tutti gli host della rete).
se prendiamo in esame la rete 192.168.32.96/27 vediamo che:
Indirizzo di rete: 11000000.10101000.00100000.01100000 (192.168.032.096)
Indirizzo di broadcast: 11000000.10101000.00100000.01111111 (255.255.255.127)
Subnet mask: 11111111.11111111.11111111.11100000 (255.255.255.224)
possiamo quindi calcolare quanti sono gli indirizzi disponibili per gli host all’interno della rete: 25 - 2 = 30, questo perchè i bit che compongono l’Host_ID sono 5 e quindi avremmo 25 indirizzi possibili, ma il primo e l’ultimo sono l’indirizzo di rete e l’indirizzo di broadcast e non possono essere usati, da cui il -2.
Si noti che la maschera di sottorete è un numero, mentre la sottorete rappresenta un insieme di indirizzi IP. È quindi possibile, e del tutto normale, che sottoreti differenti (es 192.168.0.0/16, 132.144.0.0/16) abbiano la stessa maschera di sottorete (in questo caso: 255.255.0.0). Al contrario è possibile che due indirizzi IP identici possano indicare reti diverse (di dimensioni differenti) usando subnet mask diverse, ad esempio 192.168.0.0/16 è una rete molto più grande di 192.168.0.0/24 che è una sottorete della prima rete.
La seguente tabella esemplifica i metodi di utilizzo della rappresentazione delle sottoreti.
| Notazione CIDR | Host Bits | Maschera | Host nella sottorete | Uso tipico |
|---|---|---|---|---|
| /8 | 24 | 255.0.0.0 | 16777214 = 224 - 2 | Allocazione più grande possibile per IANA |
| /9 | 23 | 255.128.0.0 | 8388608 = 223 | |
| /10 | 22 | 255.192.0.0 | 4194304 = 222 | |
| /11 | 21 | 255.224.0.0 | 2097152 = 221 | |
| /12 | 20 | 255.240.0.0 | 1048576 = 220 | |
| /13 | 19 | 255.248.0.0 | 524288 = 219 | |
| /14 | 18 | 255.252.0.0 | 262144 = 218 | |
| /15 | 17 | 255.254.0.0 | 131072 = 217 | |
| /16 | 16 | 255.255.0.0 | 65536 = 216 | |
| /17 | 15 | 255.255.128.0 | 32768 = 215 | ISP / grandi aziende |
| /18 | 14 | 255.255.192.0 | 16384 = 214 | ISP / grandi aziende |
| /19 | 13 | 255.255.224.0 | 8192 = 213 | ISP / grandi aziende |
| /20 | 12 | 255.255.240.0 | 4096 = 212 | Piccoli ISP / grandi aziende |
| /21 | 11 | 255.255.248.0 | 2048 = 211 | Piccoli ISP / grandi aziende |
| /22 | 10 | 255.255.252.0 | 1024 = 210 | |
| /23 | 9 | 255.255.254.0 | 512 = 29 | |
| /24 | 8 | 255.255.255.0 | 256 = 28 | LAN ampia |
| /25 | 7 | 255.255.255.128 | 128 = 27 | LAN ampia |
| /26 | 6 | 255.255.255.192 | 64 = 26 | Piccola LAN |
| /27 | 5 | 255.255.255.224 | 32 = 25 | Piccola LAN |
| /28 | 4 | 255.255.255.240 | 16 = 24 | Piccola LAN |
| /29 | 3 | 255.255.255.248 | 8 = 2³ | La più piccola rete multi-host |
| /30 | 2 | 255.255.255.252 | 4 = 2² | "Glue network" (collegamenti punto-punto) |
| /31 | 1 | 255.255.255.254 | 2 = 21 | Usato raramente, collegamenti punto-punto |
| /32 | 0 | 255.255.255.255 | 1 = 20 | Route verso un singolo host |
Un’analisi più approfondita di come sono formate le reti a seconda della subnet mask è la seguente in cui per semplicità sono riportate solo le reti con CIDR da 24 a 29.
| CIDR | Maschera | Indirizzi totali | Rete | Intervalli indirizzi | Broadcast |
|---|---|---|---|---|---|
| /24 | 255.255.255.0 | 256 | 0 | 1-254 | 255 |
| /25 | 255.255.255.128 | 128 | 0 128 | 1-126 129-254 | 127 255 |
| /26 | 255.255.255.192 | 64 | 0 64 128 192 | 1-62 65-126 129-190 193-254 | 63 127 191 255 |
| /27 | 255.255.255.224 | 32 | 0 32 64 96 128 160 192 224 | 1-30 33-62 65-94 97-126 129-158 161-190 193-222 225-254 | 31 63 95 127 159 191 223 255 |
| /28 | 255.255.255.240 | 16 | 0 16 32 48 64 80 96 112 128 144 160 176 192 208 224 240 | 1-14 17-30 33-46 49-62 65-78 81-94 97-110 113-126 129-142 145-158 161-174 177-190 193-206 209-222 225-238 241-254 | 15 31 47 63 79 95 111 127 143 159 175 191 207 223 239 255 |
| /29 | 255.255.255.248 | 8 | 0 8 16 24 32 40 48 56 64 72 80 88 96 104 112 120 128 136 144 152 160 168 176 184 192 200 208 216 224 232 240 248 | 1-6 9-14 17-22 25-30 33-38 41-46 49-54 57-62 65-70 73-78 81-86 89-94 97-102 105-110 113-118 121-126 129-134 137-142 145-150 153-158 161-166 169-174 177-182 185-190 193-198 201-206 209-214 217-222 225-230 233-238 241-246 249-254 | 7 15 23 31 39 47 55 63 71 79 87 95 103 111 119 127 135 143 151 159 167 175 183 191 199 207 215 223 231 239 247 255 |
Classi di indirizzi IP
Le classi di indirizzi IP (o classful addressing) sono una formalità per dividere lo spazio di indirizzamento IPv4 introdotta nel 1981 ed in uso fino all’introduzione del Classless Inter-Domain Routing (CIDR) che le ha sostituite nel 1993. Le classi vengono ancora oggi studiate e utilizzate poichè all’interno delle reti private vengono spesso utilizzati sistemi di indirizzamento basati sul sistema delle classi utilizzato come standard (non obbligatorio) per l’assegnamento degli indirizzi.
Questo sistema di indirizzamento basato sulla classe prevede che dai primi bit di un indirizzo IP si possa determinare la classe e di conseguenza la maschera di sottorete. Di seguito è riportata la tabella riassuntiva delle classi di indirizzamento.
| Utilizzo bit (N: Network; H: Host) | Maschera di sottorete | Reti disponibili | Host disponibili per rete | Range decimale primo byte | Range binario primo byte | Note | Indirizzi totali | ||
|---|---|---|---|---|---|---|---|---|---|
| Classe | A | 0NNNNNNN.HHHHHHHH.HHHHHHHH.HHHHHHHH | 255.0.0.0 /8 | 127 (1° byte) | (errato 16 777 216) 16.777.214 | 1-127 = 128 indirizzi | 00000001 - 01111110 | Loopback address | (errato 2 147 483 392) 2.130.706.648 = 127x2563 |
| B | 10NNNNNN.NNNNNNNN.HHHHHHHH.HHHHHHHH | 255.255.0.0 /16 | 16 384 (1° e 2° byte) | (errato 65 536) 65.534 | 128-191 = 64 indirizzi | 10000000 - 10111111 | (errato 1 073 709 056) 1.073.741.824 = 64x2563 | ||
| C | 110NNNNN.NNNNNNNN.NNNNNNNN.HHHHHHHH | 255.255.255.0 /24 | 2 097 152 (1°, 2° e 3° byte) | (errato 256) 254 | 192-223 = 32 indirizzi | 11000000 - 11011111 | (errato 532 676 608) 536.870.912 = 32x2563 | ||
| D | 1110XXXX.XXXXXXXX.XXXXXXXX.XXXXXXXX | 224-239 = 16 indirizzi | 11100000 - 11101111 | Indirizzo multicast | |||||
| E | 1111XXXX.XXXXXXXX.XXXXXXXX.XXXXXXXX | 240-255 = 16 indirizzi | 11110000 - 11111111 | Per usi futuri ed esperimenti | |||||
In questo modo il tipo di classe si può determinare sulla base dei bit più significativi.
Vediamo come:
Classe A
Il primo byte rappresenta la rete; gli altri tre gli host per ogni rete.
In notazione decimale gli IP variano nel modo seguente: 1-127.H.H.H;
La maschera di rete è 255.0.0.0 (o anche detta /8 in quanto i bit di rete sono 8);
Questi indirizzi in binario iniziano con il bit 0.
Classe B
I primi due byte rappresentano la rete; gli altri due gli host per ogni rete.
In notazione decimale gli IP variano nel modo seguente: 128-191.N.H.H;
N varia da 0 a 255.
La maschera di rete è 255.255.0.0 (o anche detta /16 in quanto i bit di rete sono 16);
Questi indirizzi in binario iniziano con i bit 10.
Classe C
I primi tre byte rappresentano la rete; l’ultimo gli host per ogni rete.
In notazione decimale gli IP variano nel modo seguente: 192-223.N.N.H;
La maschera di rete è 255.255.255.0 (o anche detta /24 in quanto i bit di rete sono 24);
Questi indirizzi in binario iniziano con i bit 110.
Classe D
È riservata agli indirizzi multicast.
In notazione decimale gli IP variano nel modo seguente: 224-239.x.x.x;
Non è definita una maschera di rete, essendo tutti e 32 i bit dell’indirizzo utilizzati per indicare un gruppo, non un singolo host;
Questi indirizzi in binario iniziano con i bit 1110.
Classe E
Riservata per usi futuri;
In notazione decimale gli IP variano nel modo seguente: 240-255.x.x.x;
Non è definita una maschera di rete;
Questi indirizzi in binario iniziano con i bit 1111.
Esempio:
Se occorresse analizzare l’indirizzo IP 130.165.4.2 privo di maschera di rete e fosse necessario trovarne la classe di appartenenza, si potrebbe iniziare considerando che convertito in binario il primo ottetto (il numero 130) risulterebbe 10000010, ovverosia un numero appartenente alla classe B proprio perché gli indirizzi di classe B iniziano con i primi bit a 10.
Esempio:
Se fosse necessario calcolare a mano il numero di reti e di host disponibili negli indirizzi di classe B, si effettuano i seguenti calcoli:
Numero di reti: 214 (bit di rete) = 16.384
Numero di host: 216 (bit di host) - 2 (in quanto si escludono l’indirizzo di rete e quello di broadcast) = 65.536 - 2 = 65.534
Per il calcolo della rete si effettua 214 in quanto questo è il calcolo per trovare tutte le combinazioni possibili su 14 bit. Infatti in classe B vi sono 16 bit utilizzati per la rete (vedere riferimenti alla tabella: In classe B il numero di bit per la rete N è 16) ma considerando che i primi 2 bit sono sempre fissi a 10, allora i bit che veramente possono variare scendono a 14.
Analogo discorso per il calcolo degli host, dove si effettua 216 in quanto questo è il calcolo per trovare tutte le combinazioni possibili di host su 16 bit disponibili a tale scopo (vedere riferimenti alla tabella: In classe B il numero di bit per gli host H è 16). È molto importante sottolineare come non siano mai considerati host sia l’indirizzo di broadcast (tutti i bit degli host H a 1) che l’indirizzo di rete (tutti i bit degli host H a 0); per cui nel calcolo degli host si sottrae sempre 2 al risultato ottenuto proprio per escludere questi due indirizzi particolari che non sono host.
L’intervallo di indirizzi utilizzati da ogni classe sono indicati nello schema successivo mediante notazione decimale puntata o dotted decimal notation
| Classe | Bit iniziali | Inizio intervallo | Fine intervallo |
|---|---|---|---|
| A | 0 (00000001) | 1.0.0.0 | 127.255.255.255 |
| B | 10 | 128.0.0.0 | 191.255.255.255 |
| C | 110 | 192.0.0.0 | 223.255.255.255 |
| D (multicast) | 1110 | 224.0.0.0 | 239.255.255.255 |
| E | 1111 | 240.0.0.0 | 255.255.255.255 |
Alcuni indirizzi sono riservati per usi speciali (RFC 3330).
| Indirizzi | CIDR | Funzione | RFC | Classe | Totale # indirizzi |
|---|---|---|---|---|---|
| 0.0.0.0 - 0.255.255.255 | 0.0.0.0/8 | Indirizzi zero | RFC 1700 | A | 16.777.216 |
| 10.0.0.0 - 10.255.255.255 | 10.0.0.0/8 | IP privati | RFC 1918 | A | 16.777.216 |
| 127.0.0.0 - 127.255.255.255 | 127.0.0.0/8 | Localhost Loopback Address | RFC 1700 | A | 16.777.216 |
| 169.254.0.0 - 169.254.255.255 | 169.254.0.0/16 | Indirizzo link local | RFC 3330 | B | 65.536 |
| 172.16.0.0 - 172.31.255.255 | 172.16.0.0/12 | IP privati | RFC 1918 | B | 1.048.576 |
| 192.0.2.0 - 192.0.2.255 | 192.0.2.0/24 | Documentation and Examples | RFC 3330 | C | 256 |
| 192.88.99.0 - 192.88.99.255 | 192.88.99.0/24 | IPv6 to IPv4 relay Anycast | RFC 3068 | C | 256 |
| 192.168.0.0 - 192.168.255.255 | 192.168.0.0/16 | IP privati | RFC 1918 | C | 65.536 |
| 198.18.0.0 - 198.19.255.255 | 198.18.0.0/15 | Network Device Benchmark | RFC 2544 | C | 131.072 |
| 224.0.0.0 - 239.255.255.255 | 224.0.0.0/4 | Multicast | RFC 3171 | D | 268.435.456 |
| 240.0.0.0 - 255.255.255.255 | 240.0.0.0/4 | Riservato | RFC 1700 | E | 268.435.456 |
Vista la limitatezza del numero di indirizzi disponibili, a lungo andare, le classi di tipo C si sono rivelate troppo poche per le esigenze di indirizzamento e si è dovuto assegnare subnet di grana più fine anche all’interno delle classi A e B. A partire dal 1993 si abbandonò quindi il concetto di classful routing in favore del Classless Inter-Domain Routing (CIDR).
CIDR - Classless Inter-Domain Routing
Il CIDR (Classless Inter-Domain Routing) è un nuovo schema di indirizzamento introdotto nel 1993 per sostituire lo schema classful secondo il quale tutti gli indirizzi IP appartengono ad una specifica classe (classe A, B e C).
Questo nuovo schema di indirizzamento consente una migliore gestione degli indirizzi di rete (evitando sprechi), che diventano sempre più scarsi con il crescere di Internet ed, inoltre, migliora le prestazioni dell’instradamento IP, grazie ad una più efficiente organizzazione delle tabelle di routing.
Con il sistema delle classi la divisione tra parte Net_ID e Host_ID doveva sempre avvenire tra un byte e l’altro dell’indirizzo IP avendo come uniche subnet mask disponibili:
255. 0 . 0 . 0 - 11111111.00000000.00000000.00000000 - Classe A
255.255. 0 . 0 - 11111111.11111111.00000000.00000000 - Classe B
255.255.255. 0 - 11111111.11111111.11111111.00000000 - Classe C
CIDR invece permette, in un indirizzo IP, di definire quale parte indichi la sotto rete e quale gli host, in maniera “continua” ovvero senza la suddivisione a blocchi del tipo classfull. In pratica è possibile avere subnet mask come:
255.240. 0 . 0 - 11111111.11110000.00000000.00000000
255.255.255.224 - 11111111.11111111.11111111.11100000
La notazione usata per esprimere indirizzi CIDR è la seguente: a.b.c.d/x , dove x è il numero di bit (contati partendo dal più significativo a sinistra) che compongono la parte di indirizzo della rete. I rimanenti y = (32 - x) bit consentono di calcolare il numero di host della sottorete pari a 2y - 2. Il -2 è dovuto al fatto che il primo e l’ultimo indirizzo di ogni rete non sono assegnabili ad alcun host, in quanto riservati rispettivamente come indirizzo della rete in generale (usato ad esempio nelle tabelle dei router) e come indirizzo di broadcast (ovvero un indirizzo che comprende indistintamente ogni altro indirizzo all’interno di quella rete: viene usato ad esempio in alcuni protocolli di routing).
Un esempio di indirizzo IP rappresentato secondo na notazione CIDR è 192.168.1.128/25 che rappresenta una sottorete più piccola di una classica rete di classe C. La notazione introdotta è molto compatta e comoda, in maniera classica potremmo invece scrivere:
- indirizzo IP:
192.168.1.128 - subnet mask (dotted decimal):
255.255.255.128 - subnet mask (binario):
11111111.11111111.11111111.10000000
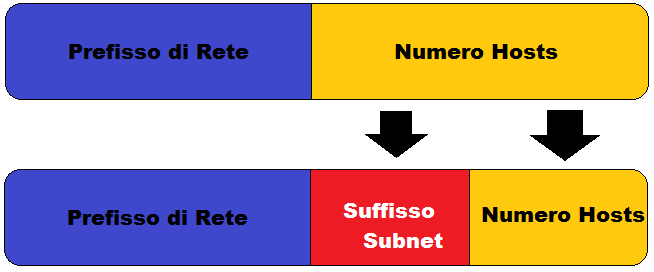
Sottoreti e Subnetting
L’operazione di subnetting rompe una rete in piccoli intervalli, che possono utilizzare lo spazio di indirizzi esistenti. Questa operazione può essere effettuata o per motivi organizzativi, di sicurezza o per impedire eccessivi tassi di collisione dei pacchetti (se la separazione è anche fisica).
Un esempio di comunicazione mascherata. In questo caso è l'indirizzo di A che è mascherato
Un esempio di comunicazione mascherata. In questo caso è l'indirizzo di A che è mascherato
Quando si vuole separare una rete in più sottoreti è necessario lavorare sui bit dell’indirizzo e sulla subnet mask della rete di partenza. La parte di Net_ID non può variare ed è possibile operare solo sui bit riguardanti l’Host_ID. Per chiarire il procedimento si procederà con un esempio.
Data la rete di partenza 192.168.1.0/24 (una classica rete privata di classe C) si vuole separare la rete in 3 differenti sottoreti. Gli indirizzi disponibili sono quelli che vanno da 192.168.1.0 a 192.168.1.255.
Subnet mask: 1111 1111 . 1111 1111 . 1111 1111 . 0000 0000
Primo indirizzo: 1100 0000 . 1010 1000 . 0000 0001 . 0000 0000
Ultimo indirizzo: 1100 0000 . 1010 1000 . 0000 0001 . 1111 1111
Per ottenere 3 sottoreti è necessario utilizzare i primi 2 bit dell’Host_ID e aggiungerli al Net_ID in modo da poter distinguere le 3 nuove sottoreti. Devo utilizzare 2 bit poichè in binario per poter rappresentare 3 numeri diversi mi servono almeno 2 bit perchè 22 = 4 > 3
Nuova subnet mask: 1111 1111 . 1111 1111 . 1111 1111 . 1100 0000
Indirizzo sottorete 1: 1100 0000 . 1010 1000 . 0000 0001 . 0000 0000
Indirizzo sottorete 2: 1100 0000 . 1010 1000 . 0000 0001 . 0100 0000
Indirizzo sottorete 3: 1100 0000 . 1010 1000 . 0000 0001 . 1000 0000
Indirizzo sottorete 4: 1100 0000 . 1010 1000 . 0000 0001 . 1100 0000
In questo modo in realtà è possibile ottenere 4 sottoreti di cui ne vengono utilizzate solo 3.
Esercizi sul subnetting
Per padroneggiare l’argomento è necessario fare pratica con esercizi che richiedano di applicare gli argomenti fin qui esposti in diverse situazioni. A questa pagina è possibile trovare una serie di esercizi con soluzioni. Qui li ho salvati in locale.
Indirizzi pubblici e privati
La separazione tra indirizzi privati e indirizzi pubblici è un sistema che ha permesso a IPv4 di rimanere in uso ancora oggi nonostante le iterfacce di rete che richiedono un indirizzo IP siano molte di più di 4 miliardi.
Questo sistema è basato sul riutilizzo di indirizzi IP all’interno di differenti reti private, in questo modo gli indirizzi IP sono univoci solo all’interno di una rete privata e lo spazio di indirizzamento è separato per ogni rete privata. L’indirizzo IP del dispositivo da cui stai leggendo questa pagina potrebbe quindi essere utilizzato da tante altre persone nel mondo che sono collegate a reti private diverse dalla tua.
Per poter far comunicare tra loro host appartenenti a differenti reti private in cui è quindi possibile che più di un host abbia un determinato indirizzo IP è necessario che almeno un host di ogni sottorete, solitamente un router, possieda un indirizzo IP pubblico che deve essere unico al mondo. è la presenza di questi router che permette la comunicazione tra host appartenenti a reti private diverse attuando un servizio chiamato NAT.
NAT
Il network address translation o NAT, ovvero traduzione degli indirizzi di rete, conosciuto anche come network masquerading, è una tecnica che consiste nel modificare gli indirizzi IP contenuti negli header dei pacchetti in transito su un sistema, solitamente un router (o un firewall ma per motivi diversi da quelli qui esposti, principalmente per la sicurezza), all’interno di una comunicazione tra due o più host.
Nel caso di comunicazione tra due host appartenenti a reti private diverse il NAT serve a fare in modo che entrambi gli host che stanno comunicando possano scrivere come IP di destinazione un indirizzo IP pubblico, quindi uivoco, che possa essere instradato correttamente tra le diverse sottoreti. Ogni host penserà di parlare con il router dell’altra sottorete, che è l’unico host di tale sottorete ad essere visibile al mondo (poichè ha un indirizzo pubbico). I router quindi devono continuamente effettuare la traduzione degli indirizzi di rete quando inoltrano i pacchetti all’interno della propria sottorete verso il destinatario.
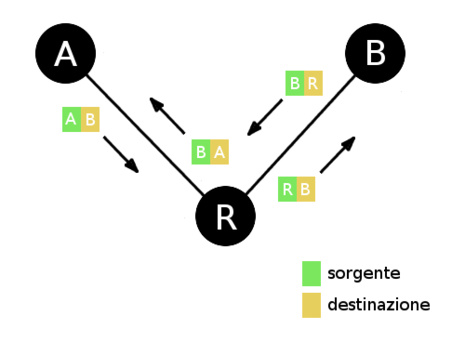
Un esempio di comunicazione mascherata. In questo caso è l'indirizzo di A che è mascherato
Un esempio di comunicazione mascherata. In questo caso è l'indirizzo di A che è mascherato
Un esempio pratico di comunicazione che richiede l’utilizzo del NAT è costituito dal computer che stai usando per leggere questa pagina che si trova in una rete privata che deve comunicare col server su cui risiede la pagina che deve essere scaricata. Nell’immagine a fianco di esempio il computer è indicato dall’host A, il router della tua rete da R e il server da B. Considera che tra R e B ci saranno tanti altri nodi appartenenti alla rete internet, così come tra A ed R è possibile che ci siano altri nodi interni alla rete locale.
A conosce l’indirizzo di B che è pubblico e scrive nell’intestazione dei pacchetti il proprio indirizzo come mittente e l’indirizzo di B come destinatario. Quando i pacchetti arrivano a R, R modifica l’indirizzo mittente col proprio indirizzo, un indirizzo pubblico, perchè altrimenti B non sarebbe in grado di rispondere poichè l’indirizzo di A è privato e nessuno nella rete internet saprebbe a chi mandare i pacchetti oppure li manderebbero alla persona sbagliata che ha un indirizzo IP pubblico identico all’indirizzo IP privato di A. B quindi risponde indicando come destinatario R e non A. R quindi quando riceve i pacchetti da B sostituisce l’indirizzo di destinazione, che B ha indicato come R, scrivendo A e inoltrando i pacchetti verso A. Eventuali nodi interni alla rete sono quindi in grado di far arrivare i pacchetti ad A.
Si pone però un problema: un router, in questo caso R, riceve continuamente pacchetti da e verso molteplici host, come fa quindi a sapere quali pacchetti sono quelli che B sta effettivamente mandando ad A e non a qualcun’altro all’interno della stessa sottorete (o anche solamente al router stesso)?
Per implementare il NAT, un router ha bisogno di effettuare il tracciamento delle connessioni, ovvero di tenere traccia di tutte le connessioni che lo attraversano. Per “connessione” in questo contesto si intende un flusso bidirezionale di pacchetti tra due host, identificati da particolari caratteristiche a livelli superiori a quello di rete (IP):
- nel caso di TCP è una connessione TCP in senso proprio, caratterizzata da una coppia di porte.
- nel caso di UDP, per quanto UDP sia un protocollo di trasporto senza connessione, viene considerata connessione uno scambio di pacchetti UDP tra due host che usino la stessa coppia di numeri di porta.
- altri protocolli vengono gestiti in modo analogo, usando caratteristiche del pacchetto a livelli superiori ad IP per identificare i pacchetti che appartengono ad una stessa connessione.
TCP e UDP sono sono protocolli di livello 4 e sono descritti nella pagina dedicata a tale livello.
Come precedentemente accennato il NAT è effettuato anche per motivi di sicurezza poichè effettuare la conversione degli indirizzi IP rende molto difficile per un host esterno alla rete comunicare con un host interno alla rete, di fatto proteggendo l’host interno da moltissimi attacchi dall’esterno. Per questo motivo anche i firewall spesso implementano il NAT (insieme ad una serie di altri sistemi).
Gestione e assegnamento degli indirizzi a livello internazionale
Gli indirizzi IP pubblici e i range di indirizzi sono rilasciati e regolamentati dall’ICANN tramite una serie di organizzazioni delegate.
La parte Net_ID degli indirizzi è assegnata dall’ICANN mentre l’assegnazione della parte Host_ID è delegata al richiedente che eventualmente può suddividerla ulteriormente per la creazione di altre sottoreti logiche (subnetting) evitando duplicazioni e sprechi di indirizzi.
Gli indirizzi IP possono essere assegnati in maniera permanente (per esempio un server che si trova sempre allo stesso indirizzo) oppure in maniera temporanea, da un intervallo di indirizzi disponibili. In particolare l’assegnazione dell’Host_Id può essere di due tipi: dinamica oppure statica. L’assegnazione dinamica è utile nel caso di dispositivi che si connettono e disconnettono frequentemente e non devono svolgere ruolo di server. Nel caso un dispositivo debba essere facilmente raggiunto da altri host, come nel caso dei server, è consigliabile un assegnamento statico in modo che l’indirizzo di tale host sia noto e sempre lo stesso (si potrebbe parzialmente risolvere il problema con un abile utilizzo dei DNS che però risulterebbe comunque facilitato e alleggerito da un assegnamento statico).
Nel tempo gli indirizzi IPv4 disponibili sono diminuiti progressivamente diventando una risosa scarsa, molto richiesta e quindi costosa. La difficile implementazione a livello globale dell’IPv6 ha portato all’introduzione di nuovi concetti, che hanno rivoluzionato la teoria e la pratica delle reti. Vanno citati l’abbandono del concetto di classi di indirizzi IP e il conseguente utilizzo sempre maggiore di indirizzi classless (privi del concetto di classe), la maschera di sottorete, la riorganizzazione gerarchica degli indirizzi mediante utilizzo massivo di NAT.
L’utilizzo di queste tecniche ha prolungato di molti anni la vita di IPv4, ma non ha risolto davvero il problema, infatti gli ultimi cinque blocchi /8 di indirizzi IPv4 sono stati assegnati dallo IANA il 3 febbraio 2011 e in Italia nell’autunno del 2020 sono stati venduti gli ultimi blocchi di indirizzi IP di classi inferiori rendendo inevitabile il passaggio all’IPv6.
IPv6
IPv6 è la versione dell’Internet Protocol designata come successore dell’IPv4. Tale protocollo introduce alcuni nuovi servizi e semplifica molto la configurazione e la gestione delle reti IP.
La sua caratteristica più importante è il più ampio spazio di indirizzamento:
IPv6 riserva 128 bit per gli indirizzi IP e gestisce 2128 (circa 3,4 × 1038) indirizzi; IPv4 riserva 32 bit per l’indirizzamento e gestisce 232 (circa 4,3 × 109) indirizzi. Quantificando con un esempio, per ogni metro quadrato di superficie terrestre, ci sono 655.570.793.348.866.943.898.599 indirizzi IPv6 unici (cioè 655.571 miliardi di miliardi o 655 triliardi), ma solo 0,000007 IPv4 (cioè solo 7 IPv4 ogni milione di metri quadrati). Per dare un’idea delle grandezze in uso, se si paragona l’indirizzo singolo ad un Quark (grandezza nell’ordine di 1 attometro), con IPv4 si raggiungerebbe il diametro dell’elica del DNA (di pochi nanometri), mentre con IPv6 si raggiungerebbe il centro della Via lattea dalla Terra (tre decine di millenni-luce). L’adozione su vasta scala di IPv6 e quindi del formato per gli indirizzi IP risolverebbe indefinitamente il problema dell’esaurimento degli indirizzi IPv4.
Storia
L’ICANN rese disponibile il protocollo IPv6 sui root nameserver dal 20 luglio 2004, ma solo dal 4 febbraio 2008 iniziò l’inserimento dei primi indirizzi IPv6 nel sistema di risoluzione dei nomi. Il 3 febbraio 2011 la IANA ha assegnato gli ultimi blocchi di indirizzo IPv4 ai 5 RIR (un blocco /8 ciascuno), anche se il protocollo IPv4 verrà utilizzato fino al 2025 circa, per dare il tempo necessario ad adeguarsi
Caratteristiche
L’indirizzamento
Il cambiamento più rilevante nel passaggio dall’IPv4 all’IPv6 è la lunghezza dell’indirizzo di rete. L’indirizzo IPv6, come definito nel RFC 2373 e nel RFC 2374 è lungo 128 bit, cioè 32 cifre esadecimali, che sono normalmente utilizzate nella scrittura dell’indirizzo come descritto più avanti.
Questo cambiamento porta il numero di indirizzi esprimibili dall’IPv6 a 2128 = 1632 ≈ 3,4 × 1038.
Una delle critiche allo spazio di indirizzamento di 128 bit è che potrebbe essere ampiamente sovradimensionato. Bisogna considerare che la ragione di un indirizzamento così ampio non è da associare alla volontà di assicurare un numero sufficiente di indirizzi, quanto al tentativo di porre rimedio alla frammentazione dello spazio di indirizzamento IPv4, conseguenza, tra le altre cose, della limitazione dello spazio di indirizzamento e della poca possibilità di prevedere a medio-lungo termine la richiesta di indirizzi. È infatti possibile che un singolo operatore di telecomunicazione abbia assegnati numerosi blocchi di indirizzi non contigui.
Come per IPv4 anche IPv6 prevede che l’instradamento sia realizzato sulla base di prefissi (oggetto delle rotte) di lunghezza variabile. Normalmente tali prefissi sono non più lunghi di 64 bit, in modo da consentire l’impiego dei 64 bit meno significativi con il solo ruolo di identificare un terminale (analogo alla divisione Net_ID e Host_ID dell’IPv4). Questo vale anche per l’accesso ad Internet di una normale abitazione, a cui verrebbero assegnati almeno 264 (1,8×1019) indirizzi pubblici, mentre per realtà che dispongono di una struttura di rete articolata in più segmenti di LAN occorre assegnare un arco di indirizzi ancora più grande (ad es. un prefisso di 56 bit, vedi RFC 6177). I primi 10 bit dell’indirizzo IPv6 descrivono genericamente il tipo di computer e l’uso che questo fa della connessione (telefono VoIP, PDA, data server, telefonia mobile ecc.)
Questa caratteristica svincola virtualmente il protocollo IPv6 dalla topologia della rete fisica, permettendo per esempio di avere lo stesso indirizzo IPv6 a prescindere dal particolare Internet service provider (ISP) che si sta usando (il cosiddetto IP personale) rendendo quindi l’indirizzo IPv6 simile ad un numero di telefono. Queste nuove caratteristiche complicano però il routing IPv6 che deve tenere conto di mappe di instradamento più complesse rispetto all’IPv4; proprio le nuove proprietà dell’indirizzamento rappresentano anche i potenziali talloni d’Achille del protocollo.
Notazione per gli indirizzi IPv6
Gli indirizzi IPv6 sono composti di 128 bit e sono rappresentati come 8 gruppi, separati da due punti, di 4 cifre esadecimali (ovvero 8 word di 16 bit ciascuna) in cui le lettere vengono scritte in forma minuscola. Ad esempio 2001:0db8:85a3:0000:1319:8a2e:0370:7344 rappresenta un indirizzo IPv6 valido.
Se uno dei gruppi – come nell’esempio – è composto da una sequenza di quattro zeri può essere contratto ad un solo zero: 2001:0db8:85a3:0:1319:8a2e:0370:7344.
Inoltre, una sequenza di zeri contigui (e una soltanto) composta da 2 o più gruppi può essere contratta con la semplice sequenza :: ovvero 2001:0db8:0000:0000:0000:8a2e:0370:7344 corrisponde a 2001:0db8:0:0:0:8a2e:0370:7344 o ancora più sinteticamente a 2001:0db8::8a2e:0370:7344
Seguendo le regole prima menzionate, se più sequenze simili si susseguono, è possibile ometterle tutte; di seguito vengono riportate varie rappresentazioni dello stesso indirizzo:
2001:0db8:0000:0000:0000:0000:1428:57ab
2001:0db8:0000:0000::1428:57ab
2001:0db8:0:0:0:0:1428:57ab
2001:0db8:0::0:1428:57ab
2001:0db8::1428:57ab
Tuttavia 2001:0db8::25de::cade non è un indirizzo valido, poiché non è possibile definire quante sequenze siano presenti nelle due lacune.
Inoltre possono essere omessi anche gli zeri iniziali di ogni gruppo: 2001:0db8:02de::0e13 corrisponde a 2001:db8:2de::e13
Gli ultimi 32 bit possono essere scritti in decimale (nella notazione dotted decimal):
::ffff:192.168.89.9
è uguale a
::ffff:c0a8:5909
ma diverso da:
::192.168.89.9
o da:
::c0a8:5909
rendendo così la sintassi IPv6 retrocompatibile con quella IPv4 con evidenti benefici.
La forma di scrittura ::ffff:1.2.3.4 è chiamata IPv4-mapped address.
Il formato ::1.2.3.4 è un IPv4-compatible address, tuttavia l’uso di questo formato è sconsigliato in quanto esso è stato deprecato
Gli indirizzi IPv4 sono facilmente trasformabili in formato IPv6. Ad esempio, se l’indirizzo decimale IPv4 è 135.75.43.52 (in esadecimale, 874B2B34), può essere convertito in 0000:0000:0000:0000:0000:FFFF:874b:2b34 (oppure in notazione ibrida 0000:0000:0000:0000:FFFF:135.74.43.52) o più brevemente ::ffff:874b:2b34. Anche in questo caso è possibile l’uso della notazione ibrida (IPv4-compatible address), usando la forma ::ffff:135.75.43.52.
Indirizzi speciali
È stato definito un certo numero di indirizzi con significati particolari. Di seguito sono riportati solo i più usati:
::/128- l’indirizzo composto da tutti zeri, detto unspecified address, viene utilizzato per indicare l’assenza di indirizzo e viene utilizzato esclusivamente a livello software, corrisponde a 0.0.0.0 in IPv4;::1/128- l’indirizzo di loopback è un indirizzo associato al dispositivo di rete che ripete come eco tutti i pacchetti che gli sono indirizzati. Corrisponde a 127.0.0.1 in IPv4;::ffff:0:0/96- l’indirizzo IPv4-mapped address è utilizzato nei dispositivi dual stack;fc00::/7- il prefisso Unique Local Addresses (ULA) è valido esclusivamente all’interno dell’organizzazione. Il suo uso è analogo alle classi private della versione IPv4 (gli IP ULA non vengono ruotati su internet).ff00::/8- il prefisso di multicast è utilizzato per gli indirizzi di multicast.
Il pacchetto IPv6
Per chi non si occupi direttamente della gestione dei pacchetti non è particolarmente rilevante conoscere in dettaglio la struttura del pacchetto IPv6 ma è bene almeno averne un’idea generale, per completezza è di seguito rappresentata e descritta.
Il pacchetto IPv6, come ogni altro pacchetto di un altro strato protocollare, si compone di due parti principali: l’header e il payload. L’header è costituito dai primi 40 byte del pacchetto e contiene 8 campi, 5 in meno rispetto all’IPv4.
| + | Bit 0–3 | 4–11 | 12–15 | 16–23 | 24–31 | |||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0-31 | Version | Traffic Class | Flow Label | |||||||||||||||||||||||||||||
| 32-63 | Payload Length | Next Header | Hop Limit | |||||||||||||||||||||||||||||
| 64 - 191 | Source Address (128 bit) | |||||||||||||||||||||||||||||||
| 192 - 319 | Destination Address (128 bit) | |||||||||||||||||||||||||||||||
- Version [4 bit] - Indica la versione del datagramma IP: per IPv6, ha valore 6 (da qui il nome IPv6).
- Traffic Class [8 bit] - Si traduce come “classe di traffico”, permette di gestire le code by priority assegnando ad ogni pacchetto una classe di priorità rispetto ad altri pacchetti provenienti dalla stessa sorgente. Viene usata nel controllo della congestione.
- Flow Label [20 bit] - Usata dal mittente per etichettare una sequenza di pacchetti come se fossero nello stesso flusso. Supporta la gestione del QoS (Quality of Service), consentendo ad esempio di specificare quali etichette abbiano via libera rispetto ad altre. Al momento, questo campo è ancora in fase sperimentale.
- Payload Length [16 bit] - È la dimensione del payload, ovvero il numero di byte di tutto ciò che viene dopo l’header. Da notare che eventuali estensioni dell’header (utili ad esempio per l’instradamento o per la frammentazione) sono considerate payload, e quindi conteggiate nella lunghezza del carico. Se il suo valore è 65.535 byte, si tratta di un pacchetto di dimensione massima, anche detto Jumbogram.
- Next Header [8 bit] - Indica quale tipo di intestazione segue l’header di base IPv6. Molto simile al campo protocol dell’header IPv4, del quale usa gli stessi valori.
- Hop Limit [8 bit] - È il limite di salti consentito, praticamente il Time to live. Il suo valore viene decrementato di 1 ogni volta che il pacchetto passa da un router: quando arriva a zero viene scartato.
- Source Address [128 bit] - Indica l’indirizzo IP del mittente del pacchetto.
- Destination Address [128 bit] - Indica l’indirizzo IP del destinatario del pacchetto. La parte successiva contiene il carico utile (payload in inglese) lungo come minimo 1280 byte o 1500 byte se la rete supporta un MTU variabile. Il carico utile può raggiungere i 65.535 byte in modalità standard o può essere di dimensioni maggiori in modalità “jumbo payload”.
Transizione all’IPv6
Nel luglio 2007 è stato presentato un Internet Draft che presenta il piano di transizione per trasformare la rete Internet, principalmente basata su protocollo IPv4, in una nuova forma principalmente basata su IPv6.(http://www.ripe.net/info/faq/IPv6-deployment.html#3) Dal momento che è praticamente certo che molti vecchi calcolatori rimarranno online senza venire aggiornati, e macchine IPv6 ed IPv4 conviveranno sulla rete per decenni, il meccanismo adottato per gestire questo periodo transitorio è il cosiddetto dual stack: ogni sistema operativo che supporta IPv6 comunicherà con le macchine IPv4 grazie a un secondo stack di protocolli IPv4 che opera in parallelo a quello IPv6. Quando il computer si connetterà ad un’altra macchina in Internet, il DNS assieme all’indirizzo di rete comunicherà anche l’informazione riguardo quale stack usare (v4 o v6) e quali protocolli sono supportati dall’altra macchina.
Vantaggi:
- Transizione morbida: possibilità di liquidare gli investimenti già fatti in hardware/software senza dover sostenere nuove spese prima del necessario;
- Piena compatibilità fra vecchie e nuove macchine e applicazioni;
Svantaggi:
- Necessità di supportare in maniera estesa l’IPv4 nella Internet e negli apparati connessi.
- Essere raggiungibili dall’universo IPv4 durante la fase di transizione costringe a mantenere un indirizzo IPv4 o una qualche forma di NAT nei gateway router. Si aggiunge quindi un livello di complessità che rende la teorica disponibilità di indirizzi non immediata.
- Problemi architetturali: in particolare non sarà possibile supportare pienamente il multihoming IPv6.
Sino a quando la connettività non sarà largamente disponibile e supportata nativamente in IPv6 dall’infrastruttura di rete, è necessario utilizzare un meccanismo di trasporto dei pacchetti IPv6 su rete IPv4 tramite la tecnologia del tunneling. Questi tunnel funzionano tramite l’incapsulamento dei pacchetti IPv6 in pacchetti IPv4. Queste tecniche non sono qui oggetto di studio.
Impostazioni di rete fondamentali
Mettendo insieme i concetti visti finora possiamo capire come un computer abbia bisogno di alcune informazioni fondamentali per poter comunicare all’interno di una rete di calcolatori. Queste informazioni sono:
- indirizzo IP, assegnabile manualmente o ottenibile automaticamente tramite DHCP;
- subnet mask necessaria a separare Net_ID e Host_ID
- indirizzo IP del gateway predefinito necessario al protocollo IP per sapere a chi indirizzare i pacchetti destinati a host esterni alla propria rete;
- indirizzo IP di un server DNS che permetta di convertire i nomi di dominio in indirizzi IP (in realtà questa informazione non è strettamente necessaria al funzionamento del protocollo IP). Anche questa impostazione può essere indicata manualmente o ottenuta automaticamente tramite DHCP.
DHCP
il Dynamic Host Configuration Protocol (in acronimo DHCP, lett. “protocollo di configurazione IP dinamica”) è un protocollo che permette ai dispositivi che si collegano ad una certa rete locale di ricevere automaticamente le impostazioni di rete necessarie a comunicare nella rete. Le impostazioni principali da ricevere sono le quattro descritte nel paragrafo precedente sulle [impostazioni di rete fondamentali][#Impostazioni_di_rete_fondamentali] (ne esistono altre ma meno rilevanti e non saranno trattate). I vantaggi offerti dal poter ottenere automaticamente tutte le impostazioni in maniera automatica invece che manuale sono:
- l’inserimento manuale è molto oneroso su reti di grandi dimensioni
- l’inserimento manuale può facilmente portare ad errori di inserimento o duplicazione di indirizzi
- le impostazioni vengono assegnate dinamicamente, quest’aspetto implica che:
- semplicità nella modifica delle impostazioni per tutta la rete
- assegnare indirizzi solo agli host effettivamente collegati alla rete con risparmio nell’uso di indirizzi IP; in reti di grandi dimensioni questo può essere molto vantaggioso
- di contro è più difficile identificare un dispositivo in rete tramite indirizzo IP perchè questo è variabile, sarà quindi necessario affidarsi a servizi come DNS (Windows ad esempio assegna dei nomi ai computer che si collegano alle reti locali in modo che possano riconoscersi tra loro).
Richiesta e attribuzione dell’indirizzo
DHCP utilizza il protocollo UDP, le porte registrate sono la 67 per il server e la 68 per il client.
Quando un calcolatore vuole ottenere un indirizzo tramite DHCP, attiva il processo DHCP client. In questo momento, il calcolatore non ha un indirizzo IP valido, quindi può operare solo a livello 2 o collegamento.

Un'immagine che mostra una sessione tipica DHCP
Un'immagine che mostra una sessione tipica DHCP
La procedura descritta dal protocollo consta di diversi handshake tra client e server, ovvero scambio di pacchetti, ovviamente tutti incapsulati in frame di livello datalink, come Ethernet:
- In primis, il client invia un pacchetto chiamato DHCPDISCOVER in broadcast, con indirizzo IP sorgente messo convenzionalmente a 0.0.0.0, e destinazione 255.255.255.255 (indirizzo di broadcast).
- Il pacchetto è ricevuto da tutti gli host presenti nello stesso dominio di broadcast, e quindi da eventuali server DHCP presenti, i quali possono rispondere (o meno) con un pacchetto di DHCPOFFER in cui propongono un indirizzo IP e gli altri parametri di configurazione al client. Questo pacchetto di ritorno è indirizzato all’indirizzo di livello datalink del client (al suo MAC address - non ha ancora un indirizzo IP) ovvero in unicast.
- Il client aspetta per un certo tempo di ricevere una o più offerte, dopodiché ne seleziona una, e invia un pacchetto di DHCPREQUEST (o DHCPACCEPT) in broadcast, indicando all’interno del pacchetto, con il campo “server identifier”, quale server ha selezionato. Anche questo pacchetto raggiunge tutti i server DHCP presenti sulla rete (direttamente o tramite un relay).
- Il server che è stato selezionato conferma l’assegnazione dell’indirizzo con un pacchetto di DHCPACK (nuovamente indirizzato in broadcast all’indirizzo di livello datalink del client, possibilmente attraverso un relay); gli altri server vengono automaticamente informati che la loro offerta non è stata scelta dal client, e che sulla sottorete è presente un altro server DHCP.
Scadenza e rinnovo degli indirizzi
A questo punto, il client è autorizzato a usare l’indirizzo ricevuto per un tempo limitato, detto tempo di lease. Prima della scadenza, dovrà tentare di rinnovarlo inviando un nuovo pacchetto DHCPREQUEST al server, che gli risponderà con un DHCPACK se vuole prolungare l’assegnazione dell’indirizzo. Questi sono normali pacchetti IP unicast scambiati tra due calcolatori che hanno indirizzi validi. Se il client non riesce a rinnovare l’indirizzo, tornerà allo stato iniziale cercando di farsene attribuire un altro.
Sicurezza
Ci sarebbero tante considerazioni da fare sugli aspetti legati alla sicurezza nell’uso di DHCP ma sarebbe troppo lungo. Se ti interessa l’argomento puoi approfondirlo sulla pagina Wikipedia dedicata a DHCP a partire da qui.
Conoscere le impostazioni di rete del proprio PC
Per conoscere le impostazioni di rete del proprio computer, in qualsiasi sistema operativo Unix-like (come nei sistemi Linux o in macOS) è sufficiente aprire una shell e digitare il comando ifconfig (o ipconfig, a seconda della distribuzione in uso).
Nei sistemi operativi Microsoft Windows, invece, con il comando ipconfig, dal prompt dei comandi (per aprirlo cerca il programma “cmd” in start), si possono avere le informazioni desiderate. per ottenere informazioni aggiuntive si può aggiungere il parametro -all (il comando diventa “ipconfig -all”). In questo modo è possibile vedere non solo le quattro informazioni sopra indicate ma anche una serie di altri dati come l’indirizzo MAC delle interfacce di rete, l’indirizzo del server DHCP e molto altro.
Mediante il ping e il traceroute (comandi del DOS, oppure programmi scritti in altri linguaggi) viene inviato un pacchetto “di prova” per misurare rispettivamente il tempo di risposta e il percorso geografico della connessione attiva. Non è detto che un host sia impostato per rispondere ai ping che vengono loro inviati. Puoi provare ad eseguire il comando “ping www.google.com” e il computer dovrebbe prima risolvere il nome di dominio nell’indirizzo IP relativo e poi spedire dei pacchetti particolari a tale indirizzo e misurare il tempo di risposta a tali messaggi. Eseguento invece il comando “tracert www.google.com” verranno contattati tutti i nodi da percorrere dal tuo computer al server www.google.com e potrai vedere i loro identificativi sia sotto forma di nomi di dominio (credo), se ci sono, che di indirizzi IP, oltre ai tempi di risposta.
Chi naviga utilizzando un router, usando tali comandi visualizzerà le informazioni relative alla propria rete privata. Le informazioni riguardo all’IP pubblico (assegnato al router) sono disponibili nel pannello di configurazione del router stesso oppure è possibile visualizzarlo tramite un sito apposito.
Protocollo ARP
Finora si è parlato delle funzionalità offerte dal livello 3, in particolare quelle del protocollo IP. Come indicato in generale nella descrizione del modello ISO/OSI ogni livello necessita delle funzionalità offerte dal livello inferiore e deve quindi interagire con esso, IP infatti quando decide la destinazione dei pacchetti da inviare (che sia ad un altro host interno alla rete o il gateway) deve chiedere al livello 2 di spedire effettivamente i pacchetti.
L’interazione tra i due livelli presenta però un problema, IP identifica gli host per mezzo degli indirizzi IP mentre i protocolli di livello 2 come ethernet o wifi identificano le interfacce di rete per mezzo degli indririzzi MAC. É quindi necessario che esista un sistema per associare gli indirizzi IP all’indirizzo MAC dello stesso dispositivo. Il protocollo che fornisce tale servizio è il protocollo ARP.
Ogni volta che un calcolatore vuole inviare un pacchetto ad un certo indirizzo IP, il protocollo ARP interviene per scoprire a quale indirizzo MAC corrisponde e comunicarlo al protocollo di livello 2 che deve incapsulare il pacchetto e spedirlo. Il protocollo ARP tiene traccia delle risposte precedentemente ottenute in una apposita memoria o cache (ARP cache) per evitare di dover utilizzare continuamente ARP prima di inviare ciascun pacchetto al destinatario (il che comporterebbe un notevole ritardo nelle comunicazioni ed una maggiore complessità nella gestione del traffico). Le informazioni contenute nella cache ARP vengono cancellate dopo un certo periodo dall’ultima occorrenza, tipicamente dopo 5 minuti.
Funzionamento
L’host che vuole conoscere il MAC address di un altro host, di cui conosce l’indirizzo IP, invia in broadcast, a livello 2, una richiesta ARP (pacchetto di ARP Request) contenente il proprio indirizzo MAC e l’indirizzo IP del destinatario di cui si vuole conoscere il MAC Address. Tutti i calcolatori della sottorete ricevono la richiesta: in ciascuno di essi il protocollo ARP verifica, confrontando l’IP proprio con quello inviato, se viene richiesto il proprio MAC Address. L’host di destinazione che riconoscerà il proprio indirizzo IP nel pacchetto di ARP-request, provvederà ad inviare una risposta (ARP Reply) contenente il proprio MAC direttamente all’host mittente (quindi in unicast).
Per altri dettagli sul funzionamento del protocollo ARP puoi guardare qui.
Router

Router domestico dotato sia di porte fisiche che di antenne per il Wi-Fi
Router domestico dotato sia di porte fisiche che di antenne per il Wi-Fi
Un router è un dispositivo di rete di livello 3 usato per collegare sottoreti diverse e che si occupa di instradare i pacchetti fra le diverse sottoreti. Il router spesso opera anche come “gestore” di una determinata sottorete fornendo una serie di servizi agli host collegati a quella sottorete.
Mentre gli switch si occupano di collegare dispositivi all’interno di una stessa rete identificandoli per mezzo di indirizzi MAC, i router si occupano di collegare diverse reti utilizzando indirizzi di livello di rete che permettendo loro di effettuare il routing dei pacchetti tra reti differenti. Ogni protocollo di rete effettua queste operazioni in maniera differente. Nel capitolo riguardante il protocollo IP è stato trattato nel dettaglio questo argomento.
Spesso le reti sono organizzate gerarchicamente tra loro e i router sono quindi solitamente costruiti per rispettare tale ordine. Spesso quindi i router presentano una porta per la connessione alla rete “esterna” e una o più porte fisiche per i collegamenti verso la rete “interna”. A volte possiedono anche antenne per fornire connessione Wi-Fi alla rete interna.
Per poter implementare il NAT i router devono essere in grado di operare parzialmente a livello di trasporto per poter analizzare le connessioni TCP e UDP.
Link e riferimenti esterni
- ISO/OSI su Wikipedia
- Livello di rete su Wikipedia
- Internet Protocol su Wikipedia
- Indirizzo IP su Wikipedia
- NAT su Wikipedia
- Classi di indirizzi IP su Wikipedia
- Maschera di sottorete o subnet mask su Wikipedia
- Esercizi di subnetting su www.edutecnica.it
- DHCP su Wikipedia
- Protocollo ARP su Wikipedia